Practicum in Trading Systems Development: Lab 4
Due:
Thursday, July 19, 2012,
by
5:00 PM
PURPOSE AND RATIONALE
The function of this lab is to let students gain specific experience
with basic thread programming in C++ using a C++11 compiler. The
goal of this lab is to provide students with the
foundations necessary to understand the dynamics of multithreading that
will be fundamental in many of the components in the
UCEE
architecture.
NB: If you are not a CSPP
student and are in need of a CS Cluster login ID (if you don't know
what this is you are in need of one), contact the TAs immediately so
you can get set up with a cluster login ID for the labs. This
course cannot be conducted without a CS Cluster login ID. If you
already have a UofC CNET ID, you can (and should) manually apply for a
CS cluster ID here.
PRIMARY RESOURCES:
You should refer to relevant sections of the man pages for assistance
for
this lab, in addition to materials in the assigned chapters from the
primary texts for
this
week (per the syllabus).
You should ssh into the cluster to perform all lab
activities.
Make sure you have read this week's assigned reading.
README
- If you are not in our course email list, please subscribe to the
cspp51025 email list here: http://mailman.cs.uchicago.edu/mailman/listinfo/cspp51025
- Turn the lab assignment as a tarball in by email to the TA
(cc'ing the instructor) by the due date
above.
- For printing out your documents, you might find the following
commands useful during your year(s) in this department:
- lpr - off line print. Note that this command is
called when you print from acroread (for .pdf files) or
gv (for .ps files)
- lpq - shows the printer queue
- lprm - removes jobs from the printer queue
- enscript - converts text files to PostScript (useful
when you want to print out text files)
- Make sure you have read the Submission Guidelines for
submission.
LAB 3
You are to multiply two matrices together, specifically, Matrix A and Matrix B.
Both of these files have exactly 300 lines each. You will use the
following algorithm to do produce the product Matrix C:
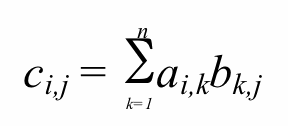
Specifically, on each iteration, a row of A multiplies a column of B,
such that:
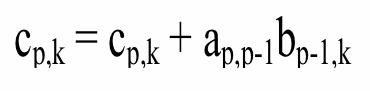
For this lab, you are to produce two solutions:
1. A single threaded version of your algorithm (one main thread)
that multiplies Matrix A and Matrix B and derives Matrix C. You
are to time that version (man time).
2. A multithreaded version of your algoritm that does the same
thing, but as specified below:
As there are 300 rows in each matrix (A and B above), you will create 6
threads (in addition to the main thread) and these 6 threads will each
multiply 50 rows each of matrix a and matrix b yielding a portion of
product C. So the first thread would concentrate on producing the
first 50 rows (0-49) of the product matrix. The second thread
will multiply the next 50 rows, namely, rows 50-99, etc. The
sixth thread will of course work on rows 250-299 (0 offset) of the
product matrix C. As part of your solution, you should make sure
that each thread calls std::thread::yield() after each 10 rows that it
processes.
There are several sources on the web (via google search) to find out
how to basically code the matrix multiplcation portion of this
lab. Here is some sample code that multiples two 3x3 matrices (A
& B) into a product matrix C (we are assuming of course that A and
B actually have data):
int i,j,k;
for
(i=1; i<=3; i++)
{
for (j=1; j<=3; j++)
{
sum = 0;
for (k=1; k<=3; k++)
sum = sum + A[i][k]*B[k][j];
}
C[i][j] = sum;
}
If you are wondering why we do not have to worry about collisions in
our product matrix (and why we are not using mutexes, etc.), the answer
is (a) we haven't covered mutexes and (b) you don't need them.
The reason why you don't need them is that matrix multiplication is one
of those embarrasingly parallel activities
that serve our initial purposes perfectly. Unless you miscode the
algorithm, you cannot possibly collide with another write.
You are to time (man time) your multithreaded version and contemplate
the results.
More information:
C++ Concurrency In Action
Website
BOOST
Threads
Threads on
cppreference.com
Mark
Shacklette