Homework 12
Be sure to include type, purpose, definition and tests for all functions.
Include the following at the top of your homework:
#lang typed/racket (require "../include/uchicago151.rkt") (require typed/test-engine/racket-tests) (require typed/2htdp/image)And include (test) at the bottom of your homework.
Submit your work in your repository in hw12/hw12.rkt by noon Monday, July 17.
Problem 1
Write the following polymorphic sorting functions. Each should have type ((A A -> Boolean) (Listof A) -> (Listof A)). The first input is an ordering function and the second is an unsorted list of items. The output is a sorted list.- isort does insertion sort
- msort does merge sort
- qsort does quick sort
-
tsort will work by first inserting every element
of the unsorted list into a correctly ordered binary search tree.
Then, that tree is converted back into a sorted list. This should
be a very short, simple function that uses some of the functions you
wrote in hw11. Use the following structure for binary search trees.
(define-struct Empty ()) (define-struct (Node A) ([value : A] [lsub : (BST A)] [rsub : (BST A)])) (define-type (BST A) (U Empty (Node A)))
Problem 2
Pascal's triangle is a triangular array of numbers named after Blaise Pascal. Each row of the triangle is formed as the sum of two numbers in the previous row. See the image below taken from Wikipedia:
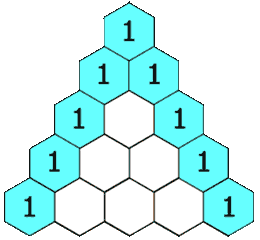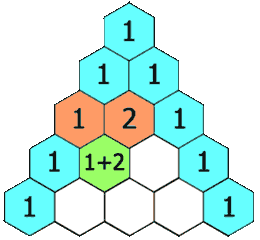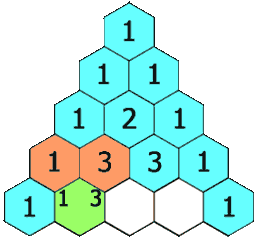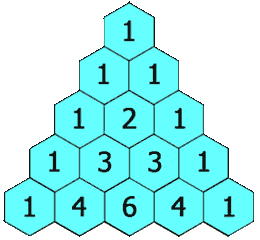
(: pascal (Positive-Integer -> (Listof (Listof Positive-Integer))))
; Creates the first n rows of Pascal's triangle
; E.g. (pascal 1) => (list (list 1))
; E.g. (pascal 2) => (list (list 1 1) (list 1))
; E.g. (pascal 3) => (list (list 1 2 1) (list 1 1) (list 1))
; E.g. (pascal 5) => (list (list 1 4 6 4 1)
(list 1 3 3 1)
(list 1 2 1)
(list 1 1)
(list 1))
Hint: start by writing a helper function that will take line n of the
triangle and compute line n+1. For example, if you give the helper
function (list 1 3 3 1) as input, the output should be
(list 1 4 6 4 1).
Problem 3
Write a function prime-list that takes a nonnegative-integer n and outputs a list of the prime numbers less than or equal to n. Hint: write a helper function that takes a number n and a list of all prime numbers less than n and returns a boolean which is true if n is prime and false otherwise.
Homework 13
Huffman coding is substantially more complex than ASCII. For the next homework, which will be due Wednesday, you will be writing functions that implement Huffman coding. I'm posting this here so you can start early if you want.
Encoding strings using huffman codes is much more complex than using ASCII. I'm posting the first part of homework 13 here so you can get started early.
You will use trees to encode the classic Huffman coding algorithm for compression of text data. As a programming exercise, Huffman coding is a mix of tree construction, counting, sorting, and other standard computational techniques. The topic of Huffman coding is treated in detail at many sites on the Web, including this one.
Introduction
Digital information is stored as binary digits—bits—and bits are
physically represented as high and low electrical signals.
Bits are written as 1 and 0, corresponding to high
and low respectively.
A byte is a bitstring of length 8.
The standard ASCII character encoding assigns one byte to each of 256
characters (256 being the number of distinct bytes that can be
represented with 0 and 1).
In ASCII, the capital A character corresponds to 01000001
(this is also the binary encoding of the number 65), B to 66, and so
on until Z to 90.
The following table shows some examples.
| character | binary encoding |
|---|---|
| A | 01000001 |
| B | 01000010 |
| C | 01000011 |
| ... | ... |
| Z | 01011010 |
We can represent the characters SHE with eight-bit ASCII
codes as follows:
01110011 01101000 01100101
In this homework we will learn an alternative efficient encoding technique
that generates shorter message encodings than ASCII.
The technique is known as Huffman coding.
Here are some insights relevant to how Huffman coding works. If a
message contains only a subset of the set of ASCII characters, it is
very likely possible to use fewer than eight bits per character. For
example, if our message is simply PIZZA, only four
letters are used. Strictly speaking, for PIZZA we only
need two bits per character: for example, 00 for
P, 01 for I, 10
for Z and 11 for A. Under that
scheme, we could represent PIZZA in just ten bits:
0001101011; in plain ASCII, by contrast, we need 8 bits
for each of the 5 characters, or 40 = 5 * 8 bits:
01010000 01001001 01011010 01011010 01000001
A second insight: if possible, we would like our more frequent characters to have shorter encodings than less frequent characters. Huffman codes use variable-length encoding for characters; not all characters are represented by the same number of bits. At scale, this can result in great savings.
These observations are the main ingredients in the Huffman coding system.
Note that variable-length encodings need to be prefix-free -- that is, the encoding of any character must not be the prefix of the encoding of any another character. This property must hold to ensure than encoded messages can be unambiguously decoded. The Huffman coding scheme produces prefix-free character encodings as a matter of course, so you need only implement the algorithm presented here to maintain prefix freedom.
To determine the Huffman codes for our characters, we start by
counting the number of occurrences of each letter in the
message. Consider the message SHESELLSSEASHELLS. (To simplify our
discussion, we only consider capital letters, and ignore every other
kind of character, including spaces.)
The frequencies in this message are
- Construct a sorted (ascending, by weight) list of singleton Huffman trees, with weights given by the calculated frequencies.
- Extract the two trees with the smallest weights from this list.
- Merge the two extracted trees into a new tree, whose weight is the combined weight of the two subtrees.
- Insert the newly-created tree back into the list such that the list still remains sorted by weight.
- Repeat from step 2, until only 1 tree remains in the list.
Running this algorithm on our example (SHESELLSSEASHELLS) produces the following tree:
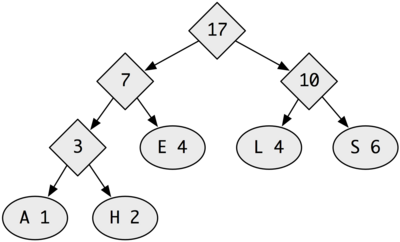
To encode a string, we compute the bitstring for each character by traversing
the path from the root to that character. Every time we move to a left
subtree we record a 0, and every time we move to a right
subtree we record a 1. For example, for this tree, we derive
001 for H.
To decode an encoded bitstring, we must be given both a bitstring and a Huffman tree. We start at the root, and move down and left for each 0, and down and right for each 1. Every time we reach a leaf, we record the letter at that leaf, and return to the root to begin reading the next letter.
Try to read the word 01011011 from the tree above. (It's
something slimy.) What about 00101011011?
To facilitate implementation, we will build augmented Huffman trees such that each leaf contains the bitstring representing the path to that leaf. This will ease the encoding process in particular. The "augmented Huffman tree" corresponding to the tree above is this:
Note that the more frequently occurring letters have shorter bit encodings.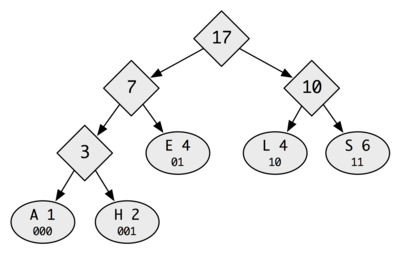
To check your understanding of Huffman coding, verify the following results with pen and paper:
- FOO → 011
- HUBBUB → 000111011
- REFEREE → 0110010111
For your implementation, assume that messages consist of ASCII characters
with values in the range
Part 1: Construct the Tree
We will use the following structures:
(define-struct Leaf ([count : Positive-Integer] [char : Char] [path : (Listof (U Zero One))])) (define-struct Node ([weight : Positive-Integer] [left : Huff] [right : Huff])) (define-type Huff (U Leaf Node)) (define-struct (Pair A B) ([a : A] [b : B]))
Write code to implement the following steps:
- Given a message, generate a list of leaves, where each number in a leaf is the occurrence count of that character. Each such leaf should have the empty list as its path.
- Sort the list of singleton trees in ascending order by count.
- Coalesce the list of trees into one big tree according to the algorithm sketched above (right above the first tree figure). Every time your program merges two trees, it must update the paths at the leaves accordingly.
Part 2: Compression
Write a function
(: compress (String -> (Pair (Listof (U Zero One)) Huff)))
to compress a plaintext message and return both the bitlist and the
Huffman tree corresponding to its encoding.
Part 3: Decompressing
Write a function
(: decompress ((Pair (Listof (U Zero One)) Huff) -> String))
to decompress a given encoded (compressed) message.
When compression and decompression are working, you should be able to feed strings into the following function and get those same strings back.
(: round-trip (-> String String))
(define (round-trip msg)
(decompress (compress msg)))
Part 4: Measure the Compression
Write a function (: measure (String -> Real)) to return the ratio of the compressed message to the raw (uncompressed) message. Measure the size of the raw message in bits: 8 times the number of characters. Measure the size of the Huffman tree and the compressed message in bits, where the size of the tree is 1 byte (8 bits) for each character in the tree, two bytes (16 bits) for each number in the tree, and 1 bit for each bit in the path at the leaves.
Submit your work in your repository in hw12/hw12.rkt by noon Monday, July 17.