Visualizing Employee Diversity Using Treemaps¶
Due: Wednesday, December 4th at 4pm.
Please note the non-standard due date.
The purpose of this assignment is to give you practice working with recursive data structures and writing recursive functions.
You must work alone on this assignment.
Introduction¶
Some of the most lucrative entry-level jobs in the U.S. are at technology companies in Silicon Valley. In recent years, greater attention has been paid to whether all people who possess the skills, regardless of gender or race, have an equal opportunity in being hired for these tech jobs. The New York Times calls this state of affairs Silicon Valley’s diversity problem, while The Guardian referred to Silicon Valley as Segregated Valley in one article. The lack of diversity in Silicon Valley tech companies has proven stubbornly persistent and may have a number of causes.
As this question has received greater attention, researchers and policymakers have begun to collect data to examine the current state of affairs more quantitatively. For example, the U.S. Equal Employment Opportunity Commission (EEOC) collected employment diversity data from a number of companies as EEO-1 Reports. This data showed that workforce diversity at Silicon Valley tech firms was quite different than at non-tech firms in Silicon Valley.
The data science site Kaggle published data from 22 Silicon Valley companies’ EEO-1 reports, enabling anyone to investigate the diversity of these companies’ workforces. This particular data set was collected by Reveal from The Center for Investigative Reporting and released under an ODbl license.
While this data is moderately interesting as a spreadsheet, it takes some careful study to get a sense of the diversity at a particular company. Rather than using a spreadsheet, the summary data can be represented hierarchically as a tree, where each sub-division is a node in the tree. For example, below we show the number of employees who identify as male and female at each of the 22 companies in the dataset. This tree represents just a part of the data (summing over all races and all job categories). Each node contains the count of employees summed across its children nodes. For example, the root node contains 354964 employees, which is the sum of the number of employees at the 22 different companies. 23andMe has 297 employees, 148 of whom identify as male and 149 of whom identify as female.
354964
│
├──23andMe: 297
│ │
│ ├──male: 148
│ │
│ └──female: 149
│
├──Adobe: 7162
│ │
│ ├──male: 4859
│ │
│ └──female: 2303
│
├──Airbnb: 1917
│ │
│ ├──male: 1095
│ │
│ └──female: 822
│
├──Apple: 77192
│ │
│ ├──male: 53456
│ │
│ └──female: 23736
│
├──Cisco: 37526
│ │
│ ├──male: 27681
│ │
│ └──female: 9845
│
├──eBay: 6611
│ │
│ ├──male: 4238
│ │
│ └──female: 2373
│
├──Facebook: 11241
│ │
│ ├──male: 7676
│ │
│ └──female: 3565
│
├──Google: 46760
│ │
│ ├──male: 33120
│ │
│ └──female: 13640
│
├──HP Inc.: 13613
│ │
│ ├──male: 9393
│ │
│ └──female: 4220
│
├──HPE: 51989
│ │
│ ├──male: 34794
│ │
│ └──female: 17195
│
├──Intel: 54135
│ │
│ ├──male: 40084
│ │
│ └──female: 14051
│
├──Intuit: 5911
│ │
│ ├──male: 3373
│ │
│ └──female: 2538
│
├──LinkedIn: 6655
│ │
│ ├──male: 3978
│ │
│ └──female: 2677
│
├──Lyft: 1433
│ │
│ ├──male: 824
│ │
│ └──female: 609
│
├──MobileIron: 506
│ │
│ ├──male: 350
│ │
│ └──female: 156
│
├──Nvidia: 5348
│ │
│ ├──male: 4429
│ │
│ └──female: 919
│
├──Pinterest: 944
│ │
│ ├──male: 537
│ │
│ └──female: 407
│
├──Salesforce: 14716
│ │
│ ├──male: 10019
│ │
│ └──female: 4697
│
├──Square: 1711
│ │
│ ├──male: 1119
│ │
│ └──female: 592
│
├──Twitter: 2952
│ │
│ ├──male: 1908
│ │
│ └──female: 1044
│
├──Uber: 5885
│ │
│ ├──male: 4149
│ │
│ └──female: 1736
│
└──View: 460
│
├──male: 382
│
└──female: 78
Each node is labeled by the particular sub-division (e.g., male or female). Note that we added a root node with no label to tie the categories together into a single tree.
While this tree representation helps us to make comparisons, once we add in the other factors (job title and race), the data will be sliced in such a way that we will lack an intuitive sense of the relative diversity at the different companies. It would be much better to see a visual representation of the data, which is the role information visualization plays in computing and in data science.
How can we visualize this information in an effective way? We can use Treemaps, which are an excellent tool for visualizing hierarchical data. Here, for example, is a treemap of gender diversity across the 22 companies:
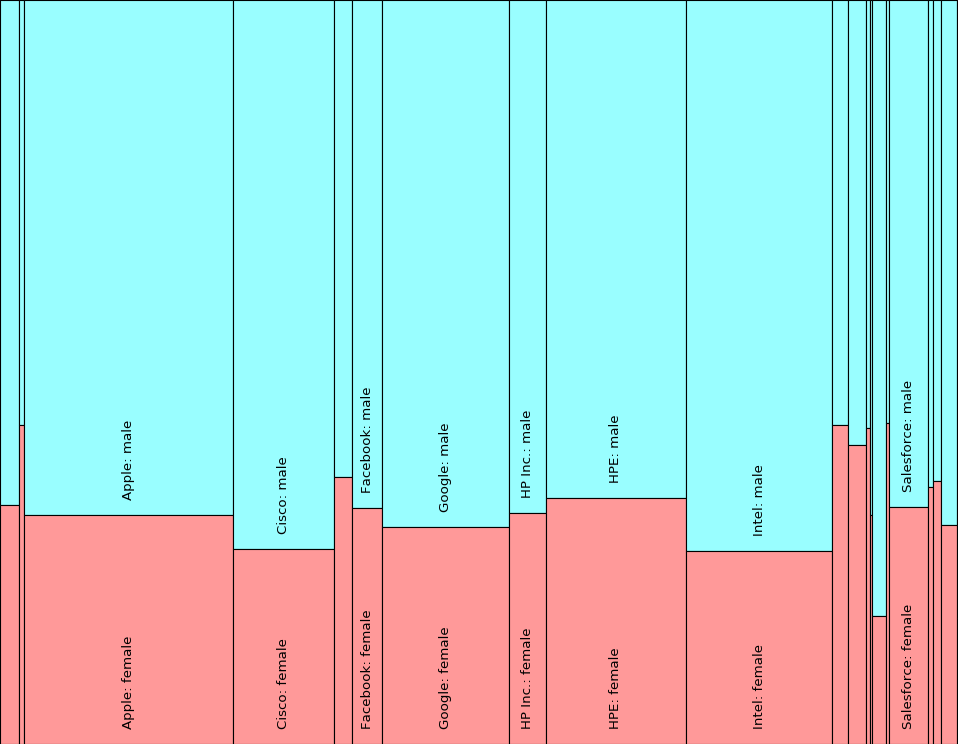
Treemap of gender diversity across companies¶
Looking at the data in this form, we can immediately see the proportion of males and females at each company, as well as how different Silicon Valley tech companies compare to each other in terms of gender diversity. The treemap also visualizes the relative size of the workforce at each company, showing that comparatively gender-balanced companies tend to have too small a workforce to even give them a legible label in the treemap.
In general, treemaps are a space-constrained method for visualizing hierarchical structures that present a sense of “mass” and proportionality in a way that the typical tree diagram shown above does not. Treemaps allow the viewer to compare leaves and sub-trees even at varying depths in the tree, and to spot patterns and exceptions. Ben Shneiderman designed treemaps during the 1990s as a way to visualize the contents of a file system. This technique has since been used to visualize many different types of data, including stock portfolios, oil production, a gene ontology, stimulus spending, and more. The original idea has been extended in many interesting ways.
In this assignment, you will write code to generate treemaps to visualize this diversity data from Silicon Valley tech companies in a number of ways.
Silicon Valley EEO-1 Data¶
We have reformatted the data collected by
Reveal
slightly and included it as a
diversity.csv file in the data directory of this programming
assignment. Each row of the dataset contains the following:
company: Company nameyear: Currently2016onlyrace: Possible values:American_Indian_Alaskan_Native,Asian,Black_or_African_American,Latino,Native_Hawaiian_or_Pacific_Islander,Two_or_more_races,Whitegender: Possible values:male,female(Non-binary gender is not included in EEO-1 reports)job_category: Possible values:Administrative support,Craft workers,Executive/Senior officials & Mgrs,First/Mid officials & Mgrs,laborers and helpers,operatives,Professionals,Sales workers,Service workers,Technicianscount: For the job category, company, race, and gender specified by that row, an integer representing the number of employees (as of 2016) in that job category at that company who identify with that race and gender
Note that this data is in CSV format. As an example, the row
"Adobe",2016,"Latino","male","Professionals",75 indicates that in 2016,
Adobe had 75 employees in the job category Professionals who identified
as Latino and male. Because the data includes 22 companies, the csv file
contains a header row plus 3080 data rows (22 companies * 2 gender categories *
7 race categories * 10 job categories). In total, this CSV file contains
data about 354,964 employees at those 22 companies.
We have also included a diversity-small.csv file that only includes data from
Apple, Google, and Facebook, for races Asian, Latino, and White, and
for job categories Executive/Senior officials & Mgrs and Professionals.
You may find this file useful when debugging your code.
Getting started¶
We have seeded your repository with a directory for this assignment.
To pick it up, change to your capp30121-aut-19-username directory
(where the string username should be replaced with your username)
and then run the command: git pull upstream master. You should
also run git pull to make sure your local copy of your repository
is in sync with the server.
The pa7/ directory contains several Python files, but you will
only be modifying one of them: treemap.py. The rest of the
files are described throughout the assignment.
As usual, you will be able to test your code from IPython and by using py.test.
When using IPython, make sure to enable autoreload before importing the Python
files we will use in this assignment:
In [1]: %load_ext autoreload
In [2]: %autoreload 2
In [3]: import treemap, drawing
In [4]: import tree as tr
Like previous assignments, we also include a series of automated tests. These
tests require an additional set of files, which you can download by running
the following from inside the data/ directory:
./get_files.sh
Test running times
Running the complete set of tests can take a while (it takes about 30 seconds
on our machines, and around 60 seconds on the Continuous Integration server).
When working on an individual task, make sure to use the -k parameter to py.test
to run only the tests for that task.
Furthermore, the tests use two datasets:
a small one and a full one. The tests with the small dataset
take less than 2 seconds to run, so we encourage you to always start by running
the tests with that dataset before you run the tests with the full dataset.
Task 0¶
This task will have zero impact on your grade. If you do it, we will not grade it. If you don’t do it, you won’t lose points for it. However, we strongly encourage you to do it, as it will ensure that you understand how to work with the data before moving on to the following tasks.
Your warm-up task is to complete the following function in treemap.py:
def load_diversity_data(filename, debug=False):
In this function, we already read in the data from the CSV file and store it
in a pandas DataFrame. Modify this function so that, if parameter debug
is True, the function also prints out the following basic summary statistics to
give a high-level view of the data:
A list of all of the distinct companies included in the dataset and the length of this list. Do not include any counts of employees for the companies.
The total number employees iare included in the dataset across all companies
Summarize how many employees of each gender are included in the dataset
Summarize how many employees of each race are included in the dataset
Summarize how many employees of each job_category are included in the dataset
Your code should generalize. For example, it should calculate the number of companies from the dataframe, rather than using a hard-coded value of 22. You should compute these summary statistics primarily using the pandas Python package. An example output follows. Your output does not have to match the one below
Diversity data comes from the following 22 companies:
23andMe, Adobe, Airbnb, Apple, Cisco, eBay, Facebook,
Google, HP Inc., HPE, Intel, Intuit, LinkedIn, Lyft,
MobileIron, Nvidia, Pinterest, Salesforce, Square, Twitter,
Uber, View
The data includes 354964 employees
#############
gender
#############
female : 107352
male : 247612
#############
race
#############
American_Indian_Alaskan_Native : 1165
Asian : 96171
Black_or_African_American : 17832
Latino : 25767
Native_Hawaiian_or_Pacific_Islander : 1146
Two_or_more_races : 5871
White : 207012
#############
job_category
#############
Administrative support : 18792
Craft workers : 543
Executive/Senior officials & Mgrs : 3536
First/Mid officials & Mgrs : 52036
Professionals : 204025
Sales workers : 42615
Service workers : 904
Technicians : 32057
laborers and helpers : 190
operatives : 266
Testing Task 0¶
Since this task simply involves printing some data, it has no associated automated tests. However, you can informally verify the correct output is being produced by running the following in IPython:
In [1]: data = treemap.load_diversity_data("data/diversity.csv", debug=True)
This should produce output similar to the one shown above.
You should also make sure your function works correctly for the smaller dataset:
In [2]: data = treemap.load_diversity_data("data/diversity-small.csv", debug=True)
This should produce output similar to this:
Diversity data comes from the following 3 companies: Apple, Facebook, Google
The data includes 61558 employees
#############
gender
#############
female : 15236
male : 46322
#############
race
#############
Asian : 25429
Latino : 3024
White : 33105
#############
job_category
#############
Executive/Senior officials & Mgrs : 602
Professionals : 60956
To reiterate, it is not necessary to match this formatting precisely. However, the values should be the ones shown above.
Representing trees¶
While storing this data in a dataframe allows us to start examining the data, drawing a treemap will be much easier if we represent the data as a tree. We will construct the tree such that each level of the tree represents a particular employee characteristic. For instance, one level of the tree might represent job categories, while another level of the tree might represent gender.
We provide a class, Tree in the file tree.py,
that you can use to represent tree data. The
class is useful for representing the diversity data, but it is not
specific to the diversity data.
Take into account that this is not the exact same Tree class we saw in class,
although it is largely similar: a Tree object
represents a node on a tree, each node has a few attributes,
and the node’s children are stored in a list. The public interface for this
class includes:
a constructor for creating a tree node,
public attributes
count(integer),label(string), andverbose_label(string).a list of children nodes
a method,
num_children, that returns the number of children the node hasa method,
print, for printing the tree rooted at that node for debugging purposes
We can use this class to represent our employee diversity data by using the
count attribute to hold the number of employees and the label attribute
to hold the name of the category that node represents. For instance, in the
gender level of the tree, a label would be either female or male.
Note that, for all levels other than the first non-root level of the tree,
multiple nodes on that level can (and should) have the same label.
We will use the attribute verbose_label to store a string representation
of the full path to a node, which we will use when
displaying the treemap. We elaborate on this requirement in Task 1.
If you are wondering why we are using generic names —label and count— rather than diversity category or number of employees, it is because this approach allows your treemap implementation to generalize to situations beyond employment diversity data.
We provide the following function, data_to_tree, that creates a tree
from a pandas DataFrame following a specified hierarchy. Note that it does
so by calling a helper function, create_st, which recursively creates
sub-trees.
def data_to_tree(data, hierarchy):
'''
Converts a pandas DataFrame to a tree (using Tree) following a
specified hierarchy
Inputs:
data: (pandas.DataFrame) the data to be represented as a tree
hierarchy: (list of strings) a list of column names to be used as
the levels of the tree in the order given. Note that all
strings in the hierarchy must correspond to column names
in data
Returns: a tree (using the Tree class) representation of data
'''
A sample call of data_to_tree follows:
In [8]: data = treemap.load_diversity_data("data/diversity.csv")
In [9]: example_tree = tr.data_to_tree(data, ["company", "gender"])
In [10]: example_tree.print()
│
├──23andMe
│ │
│ ├──male: 148
│ │
│ └──female: 149
│
├──Adobe
│ │
│ ├──male: 4859
│ │
│ └──female: 2303
│
├──Airbnb
│ │
│ ├──male: 1095
│ │
│ └──female: 822
│
├──Apple
│ │
│ ├──male: 53456
│ │
│ └──female: 23736
│
├──Cisco
│ │
│ ├──male: 27681
│ │
│ └──female: 9845
│
├──eBay
│ │
│ ├──male: 4238
│ │
│ └──female: 2373
│
├──Facebook
│ │
│ ├──male: 7676
│ │
│ └──female: 3565
│
├──Google
│ │
│ ├──male: 33120
│ │
│ └──female: 13640
│
├──HP Inc.
│ │
│ ├──male: 9393
│ │
│ └──female: 4220
│
├──HPE
│ │
│ ├──male: 34794
│ │
│ └──female: 17195
│
├──Intel
│ │
│ ├──male: 40084
│ │
│ └──female: 14051
│
├──Intuit
│ │
│ ├──male: 3373
│ │
│ └──female: 2538
│
├──LinkedIn
│ │
│ ├──male: 3978
│ │
│ └──female: 2677
│
├──Lyft
│ │
│ ├──male: 824
│ │
│ └──female: 609
│
├──MobileIron
│ │
│ ├──male: 350
│ │
│ └──female: 156
│
├──Nvidia
│ │
│ ├──male: 4429
│ │
│ └──female: 919
│
├──Pinterest
│ │
│ ├──male: 537
│ │
│ └──female: 407
│
├──Salesforce
│ │
│ ├──male: 10019
│ │
│ └──female: 4697
│
├──Square
│ │
│ ├──male: 1119
│ │
│ └──female: 592
│
├──Twitter
│ │
│ ├──male: 1908
│ │
│ └──female: 1044
│
├──Uber
│ │
│ ├──male: 4149
│ │
│ └──female: 1736
│
└──View
│
├──male: 382
│
└──female: 78
This builds a tree similar to the company-by-company breakdown of employees’ genders shown in the introduction. The tree returned, however, lacks counts for the internal (non-leaf) nodes, which you will add in Task 1.
The absence of these counts is more evident when creating a deeper tree with more categories:
In [12]: data_small = treemap.load_diversity_data("data/diversity-small.csv")
In [13]: example_tree = tr.data_to_tree(data_small, ["company", "job_category", "race", "gender"])
In [14]: example_tree.print()
│
├──Apple
│ │
│ ├──Executive/Senior officials & Mgrs
│ │ │
│ │ ├──Asian
│ │ │ │
│ │ │ ├──male: 10
│ │ │ │
│ │ │ └──female: 4
│ │ │
│ │ ├──Latino
│ │ │ │
│ │ │ ├──male: 2
│ │ │ │
│ │ │ └──female: 0
│ │ │
│ │ └──White
│ │ │
│ │ ├──male: 73
│ │ │
│ │ └──female: 15
│ │
│ └──Professionals
│ │
│ ├──Asian
│ │ │
│ │ ├──male: 6972
│ │ │
│ │ └──female: 2650
│ │
│ ├──Latino
│ │ │
│ │ ├──male: 799
│ │ │
│ │ └──female: 382
│ │
│ └──White
│ │
│ ├──male: 9012
│ │
│ └──female: 2635
│
├──Facebook
│ │
│ ├──Executive/Senior officials & Mgrs
│ │ │
│ │ ├──Asian
│ │ │ │
│ │ │ ├──male: 74
│ │ │ │
│ │ │ └──female: 30
│ │ │
│ │ ├──Latino
│ │ │ │
│ │ │ ├──male: 9
│ │ │ │
│ │ │ └──female: 7
│ │ │
│ │ └──White
│ │ │
│ │ ├──male: 254
│ │ │
│ │ └──female: 94
│ │
│ └──Professionals
│ │
│ ├──Asian
│ │ │
│ │ ├──male: 2440
│ │ │
│ │ └──female: 1112
│ │
│ ├──Latino
│ │ │
│ │ ├──male: 209
│ │ │
│ │ └──female: 133
│ │
│ └──White
│ │
│ ├──male: 2830
│ │
│ └──female: 983
│
└──Google
│
├──Executive/Senior officials & Mgrs
│ │
│ ├──Asian
│ │ │
│ │ ├──male: 6
│ │ │
│ │ └──female: 0
│ │
│ ├──Latino
│ │ │
│ │ ├──male: 0
│ │ │
│ │ └──female: 0
│ │
│ └──White
│ │
│ ├──male: 20
│ │
│ └──female: 4
│
└──Professionals
│
├──Asian
│ │
│ ├──male: 8622
│ │
│ └──female: 3509
│
├──Latino
│ │
│ ├──male: 1107
│ │
│ └──female: 376
│
└──White
│
├──male: 13883
│
└──female: 3302
Note that we used the small dataset in the above example because, otherwise,
the output would be too long to include here. However, we encourage you
to play around with the data_to_tree function (along with the tree’s
print method) with the full dataset. You’ll notice that this simple
use of trees can already give you more insights into the data that by just
looking at the numbers in a spreadsheet.
Task 1: Counts and verbose labels¶
The tree we return from data_to_tree only includes a value for the
count attribute in the leaf nodes (in all other nodes, the value
is set to None). Furthermore,
the verbose_label attribute is None for all nodes. In Task 1, you will
complete the following two recursive functions in treemap.py to
respectively compute count for all internal nodes and to set the
verbose_label for all nodes (note: the verbose label of the root
node should just be an empty string).
Your solution to each must be recursive. Non-recursive solutions (i.e., functions that do not call themselves with an input that is in some way smaller) will not receive credit for this task. Furthermore, each function should be generalizable, working for a tree of any depth. As a guideline, in our implementation each of these functions requires fewer than ten lines of code.
def compute_internal_counts(t):
'''
Assign a count to the interior nodes. The count of the leaves
should already be set. The count of an internal node is the sum
of the counts of its children.
Inputs:
t (Tree): a tree
Returns:
The input tree t should be modified so that every internal node's
count is set to be the sum of the counts of its children.
The return value will be:
- If the tree has no children: the value of the count attribute
- If the tree has children: the sum of the counts of the children
'''
def compute_verbose_labels(t, prefix=None):
'''
Assign a verbose label to all nodes. Verbose labels contain the
full path to that node through the tree. For example, following the
path "Google" --> "female" --> "white" should create the verbose label
"Google: female: white". For the root node, the verbose label should be
an empty string ("").
Inputs:
t: a tree
prefix (string): Prefix to add to verbose label
Outputs:
Nothing. The input tree t should be modified to contain
verbose labels for all nodes
'''
Testing Task 1¶
You can informally test these functions from IPython by printing
out the tree after calling one of these functions, and checking whether
whether the count or verbose_label are set correctly.
We suggest you use the small dataset, which is easier to check manually.
For example, you can check compute_internal_counts as follows:
In [23]: data_small = treemap.load_diversity_data("data/diversity-small.csv")
In [24]: tree_small = tr.data_to_tree(data_small, ["company", "race", "gender"])
In [25]: treemap.compute_internal_counts(tree_small)
Out[25]: 61558
In [26]: tree_small.print()
: 61558
│
├──Apple: 22554
│ │
│ ├──Asian: 9636
│ │ │
│ │ ├──male: 6982
│ │ │
│ │ └──female: 2654
│ │
│ ├──Latino: 1183
│ │ │
│ │ ├──male: 801
│ │ │
│ │ └──female: 382
│ │
│ └──White: 11735
│ │
│ ├──male: 9085
│ │
│ └──female: 2650
│
├──Facebook: 8175
│ │
│ ├──Asian: 3656
│ │ │
│ │ ├──male: 2514
│ │ │
│ │ └──female: 1142
│ │
│ ├──Latino: 358
│ │ │
│ │ ├──male: 218
│ │ │
│ │ └──female: 140
│ │
│ └──White: 4161
│ │
│ ├──male: 3084
│ │
│ └──female: 1077
│
└──Google: 30829
│
├──Asian: 12137
│ │
│ ├──male: 8628
│ │
│ └──female: 3509
│
├──Latino: 1483
│ │
│ ├──male: 1107
│ │
│ └──female: 376
│
└──White: 17209
│
├──male: 13903
│
└──female: 3306
You can check compute_verbose_labels as follows (note how the print
method has an optional argument to print the verbose labels):
In [27]: data_small = treemap.load_diversity_data("data/diversity-small.csv")
In [28]: tree_small = tr.data_to_tree(data_small, ["company", "race", "gender"])
In [29]: treemap.compute_verbose_labels(tree_small)
In [30]: tree_small.print(verbose=True)
│
├──Apple
│ │
│ ├──Apple: Asian
│ │ │
│ │ ├──Apple: Asian: male: 6982
│ │ │
│ │ └──Apple: Asian: female: 2654
│ │
│ ├──Apple: Latino
│ │ │
│ │ ├──Apple: Latino: male: 801
│ │ │
│ │ └──Apple: Latino: female: 382
│ │
│ └──Apple: White
│ │
│ ├──Apple: White: male: 9085
│ │
│ └──Apple: White: female: 2650
│
├──Facebook
│ │
│ ├──Facebook: Asian
│ │ │
│ │ ├──Facebook: Asian: male: 2514
│ │ │
│ │ └──Facebook: Asian: female: 1142
│ │
│ ├──Facebook: Latino
│ │ │
│ │ ├──Facebook: Latino: male: 218
│ │ │
│ │ └──Facebook: Latino: female: 140
│ │
│ └──Facebook: White
│ │
│ ├──Facebook: White: male: 3084
│ │
│ └──Facebook: White: female: 1077
│
└──Google
│
├──Google: Asian
│ │
│ ├──Google: Asian: male: 8628
│ │
│ └──Google: Asian: female: 3509
│
├──Google: Latino
│ │
│ ├──Google: Latino: male: 1107
│ │
│ └──Google: Latino: female: 376
│
└──Google: White
│
├──Google: White: male: 13903
│
└──Google: White: female: 3306
To run the automated tests for this task only with the small dataset,
you can run the following:
$ py.test -x -v -k "count and small"
$ py.test -x -v -k "verbose and small"
To run all the Task 1 tests (with both the small and full datasets), run this:
$ py.test -x -v -k count
$ py.test -x -v -k verbose
Task 2¶
Rather than always creating a treemap of the full set of data, you might first want to subset the data. For example, rather than trying to look at a particular small area of interest to you in a larger treemap, you could prune the tree, which involves removing nodes (and their children) that have a particular characteristic.
In this task, you will write a function that takes as input a tree, as well
as a list of labels identifying nodes to discard (values_to_discard).
Your function must recursively traverse the tree, returning a copy of this
original tree with all nodes whose labels are in values_to_discard
removed, along with their children. Do not modify the original tree.
You may assume (without needing to verify) that values_to_discard does
not contain all labels for a particular level. If it did contain all labels
for a particular level (e.g., it included both male and female),
no employees would be left in the tree, and the tree’s structure would also
be broken. Do not worry about that case.
In particular, you will complete the following function:
def prune_tree(original_sub_tree, values_to_discard):
'''
Returns a tree with any node whose label is in the list values_to_discard
(and thus all of its children) pruned. This function should return a copy
of the original tree and should not destructively modify the original tree.
The pruning step must be recursive.
Inputs:
t (Tree): a tree
values_to_discard (list of strings): A list of strings specifying the
labels of nodes to discard
Returns: a new Tree object representing the pruned tree
'''
If this function is called on a tree on which we have previously
called compute_internal_counts, the counts for internal nodes will
change if part of the tree is pruned. You do not need to re-compute
these internal node counts and, instead the copy of the tree your function
returns should contain count for all leaf nodes, but set count to None
for all internal nodes.
Keep in mind that this task (like others in this assignment)
is conceptually complex, yet does not require much code.
Our prune_tree implementation contains fewer than 10 lines of code.
Testing Task 2¶
We suggest you start by testing your function on the small dataset.
Let’s start by loading the tree with two levels, company and gender:
In [103]: data_small = treemap.load_diversity_data("data/diversity-small.csv")
In [104]: tree_small = tr.data_to_tree(data_small, ["company", "gender"])
In [105]: treemap.compute_internal_counts(tree_small)
Out[105]: 61558
In [106]: tree_small.print()
: 61558
│
├──Apple: 22554
│ │
│ ├──male: 16868
│ │
│ └──female: 5686
│
├──Facebook: 8175
│ │
│ ├──male: 5816
│ │
│ └──female: 2359
│
└──Google: 30829
│
├──male: 23638
│
└──female: 7191
Here is the result of pruning Facebook:
In [108]: pruned_tree = treemap.prune_tree(tree_small, ["Facebook"])
In [109]: pruned_tree.print()
│
├──Apple
│ │
│ ├──male: 16868
│ │
│ └──female: 5686
│
└──Google
│
├──male: 23638
│
└──female: 7191
Here is the result of pruning male:
In [111]: pruned_tree = treemap.prune_tree(tree_small, ["male"])
In [112]: pruned_tree.print()
│
├──Apple
│ │
│ └──female: 5686
│
├──Facebook
│ │
│ └──female: 2359
│
└──Google
│
└──female: 7191
And here is the result of pruning Facebook, Apple, and male. This
highlights how we can specify multiple labels per level, as well as labels
in multiple levels:
In [113]: pruned_tree = treemap.prune_tree(tree_small, ["Facebook", "male", "Apple"])
In [114]: pruned_tree.print()
│
└──Google
│
└──female: 7191
Finally, here is an example with the full dataset. Once again, notice how we can prune multiple labels across multiple levels:
In [115]: data = treemap.load_diversity_data("data/diversity.csv")
In [116]: tree_full = tr.data_to_tree(data, ["job_category", "race", "gender"])
In [117]: treemap.compute_internal_counts(tree_full)
Out[117]: 354964
In [118]: pruned_tree = treemap.prune_tree(tree_full, ["Technicians", "Sales workers", "Two_or_more_races", "male"])
In [119]: pruned_tree.print()
│
├──Administrative support
│ │
│ ├──American_Indian_Alaskan_Native
│ │ │
│ │ └──female: 78
│ │
│ ├──Asian
│ │ │
│ │ └──female: 1363
│ │
│ ├──Black_or_African_American
│ │ │
│ │ └──female: 1349
│ │
│ ├──Latino
│ │ │
│ │ └──female: 1614
│ │
│ ├──Native_Hawaiian_or_Pacific_Islander
│ │ │
│ │ └──female: 62
│ │
│ └──White
│ │
│ └──female: 6950
│
├──Craft workers
│ │
│ ├──American_Indian_Alaskan_Native
│ │ │
│ │ └──female: 1
│ │
│ ├──Asian
│ │ │
│ │ └──female: 5
│ │
│ ├──Black_or_African_American
│ │ │
│ │ └──female: 0
│ │
│ ├──Latino
│ │ │
│ │ └──female: 4
│ │
│ ├──Native_Hawaiian_or_Pacific_Islander
│ │ │
│ │ └──female: 0
│ │
│ └──White
│ │
│ └──female: 22
│
├──Executive/Senior officials & Mgrs
│ │
│ ├──American_Indian_Alaskan_Native
│ │ │
│ │ └──female: 1
│ │
│ ├──Asian
│ │ │
│ │ └──female: 157
│ │
│ ├──Black_or_African_American
│ │ │
│ │ └──female: 19
│ │
│ ├──Latino
│ │ │
│ │ └──female: 31
│ │
│ ├──Native_Hawaiian_or_Pacific_Islander
│ │ │
│ │ └──female: 0
│ │
│ └──White
│ │
│ └──female: 578
│
├──First/Mid officials & Mgrs
│ │
│ ├──American_Indian_Alaskan_Native
│ │ │
│ │ └──female: 39
│ │
│ ├──Asian
│ │ │
│ │ └──female: 3871
│ │
│ ├──Black_or_African_American
│ │ │
│ │ └──female: 550
│ │
│ ├──Latino
│ │ │
│ │ └──female: 864
│ │
│ ├──Native_Hawaiian_or_Pacific_Islander
│ │ │
│ │ └──female: 54
│ │
│ └──White
│ │
│ └──female: 10046
│
├──laborers and helpers
│ │
│ ├──American_Indian_Alaskan_Native
│ │ │
│ │ └──female: 0
│ │
│ ├──Asian
│ │ │
│ │ └──female: 20
│ │
│ ├──Black_or_African_American
│ │ │
│ │ └──female: 20
│ │
│ ├──Latino
│ │ │
│ │ └──female: 38
│ │
│ ├──Native_Hawaiian_or_Pacific_Islander
│ │ │
│ │ └──female: 0
│ │
│ └──White
│ │
│ └──female: 22
│
├──operatives
│ │
│ ├──American_Indian_Alaskan_Native
│ │ │
│ │ └──female: 0
│ │
│ ├──Asian
│ │ │
│ │ └──female: 3
│ │
│ ├──Black_or_African_American
│ │ │
│ │ └──female: 11
│ │
│ ├──Latino
│ │ │
│ │ └──female: 9
│ │
│ ├──Native_Hawaiian_or_Pacific_Islander
│ │ │
│ │ └──female: 0
│ │
│ └──White
│ │
│ └──female: 22
│
├──Professionals
│ │
│ ├──American_Indian_Alaskan_Native
│ │ │
│ │ └──female: 165
│ │
│ ├──Asian
│ │ │
│ │ └──female: 22410
│ │
│ ├──Black_or_African_American
│ │ │
│ │ └──female: 2449
│ │
│ ├──Latino
│ │ │
│ │ └──female: 3226
│ │
│ ├──Native_Hawaiian_or_Pacific_Islander
│ │ │
│ │ └──female: 302
│ │
│ └──White
│ │
│ └──female: 28145
│
└──Service workers
│
├──American_Indian_Alaskan_Native
│ │
│ └──female: 2
│
├──Asian
│ │
│ └──female: 46
│
├──Black_or_African_American
│ │
│ └──female: 17
│
├──Latino
│ │
│ └──female: 137
│
├──Native_Hawaiian_or_Pacific_Islander
│ │
│ └──female: 6
│
└──White
│
└──female: 104
To run the automated tests for this task only with the small dataset,
you can run the following:
$ py.test -x -v -k "prune and small"
To run all the Task 1 tests (with both the small and full datasets), run this:
$ py.test -x -v -k prune
Drawing Treemaps¶
Recall that a treemap looks like this:
Notice how all the individual shapes in the diagram are all rectangles. In fact, drawing a treemap mostly involves figuring out the exact rectangles we need to draw on a “canvas”. Our canvas is a coordinate system from (0.0, 0.0) (the top-left corner) to (1.0, 1.0) (the bottom-right corner). This is often referred to as the bounding rectangle, because it describes the bounds of where we can “draw” things (in this case, rectangles)
An individual rectangle is specified by providing its origin point (the position of the top-left corner of the rectangle) and its size (its width along the x axis and its height along the y axis).
We provide a simple Rectangle class in treemap.py and
a draw_rectangles function in drawing.py that will
visualize a list of rectangles. For example, the following
code draws a rectangle with origin (0.25, 0.5), width 0.75 and height 0.25:
In [45]: r = treemap.Rectangle((0.25,0.5), (0.75, 0.25), "Example", "Example Rectangle")
In [46]: drawing.draw_rectangles([r])
This will open a window that displays something like this:
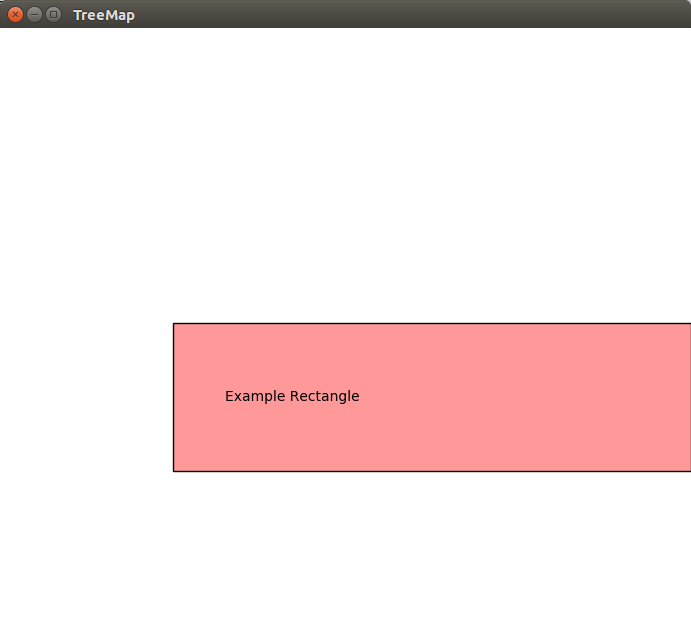
Note: you must close this window before you can continue entering code in IPython.
The following code draws two rectangles:
In [54]: r1 = treemap.Rectangle((0.20,0.20), (0.20, 0.60), "Example 1", "Example Rectangle 1")
In [55]: r2 = treemap.Rectangle((0.60,0.20), (0.20, 0.60), "Example 2", "Example Rectangle 2")
In [56]: drawing.draw_rectangles([r1, r2])
And will show something like this:

So, we need to figure out exactly what rectangles to generate (and with what positions and sizes) for a given tree.
To figure out the size of the rectangles, we will rely on
the counts computed by compute_internal_counts.
We will refer to the count we computed as the weight of a given node;
as we’ll see, this will make more sense in the context of
the treemap algorithm.
For example, consider this tree with only one employer, and with the internal counts already computed:
: 22554
│
└──Apple: 22554
│
├──Asian: 9636
│ │
│ ├──male: 6982
│ │
│ └──female: 2654
│
├──Latino: 1183
│ │
│ ├──male: 801
│ │
│ └──female: 382
│
└──White: 11735
│
├──male: 9085
│
└──female: 2650
The Apple: White subtree has two leaf nodes with weights 9085 and 2650.
The weight of the White node is the sum of those weights and, in turn,
the weight of the Apple node is the sum of the weights of Asian,
Latino, and White.
Once the tree is decorated with the correct weights (counts),
we need to divide
our bounding rectangle into a collection of smaller rectangles
based on the shape of the tree and the distribution of the weights
(this is also known as the mass of the rectangles).
Each rectangle in the resulting partition will have an
associated label: the verbose_label for that node.
To describe how regions of the bounding rectangle are allocated in the treemap algorithm, we will start by looking at the following tree, which divides the dataset only by job category:
In [57]: data = treemap.load_diversity_data("data/diversity.csv")
In [58]: tree_full = tr.data_to_tree(data, ["job_category"])
In [59]: treemap.compute_internal_counts(tree_full)
Out[59]: 354964
In [60]: tree_full.print()
: 354964
│
├──Administrative support: 18792
│
├──Craft workers: 543
│
├──Executive/Senior officials & Mgrs: 3536
│
├──First/Mid officials & Mgrs: 52036
│
├──laborers and helpers: 190
│
├──operatives: 266
│
├──Professionals: 204025
│
├──Sales workers: 42615
│
├──Service workers: 904
│
└──Technicians: 32057
The treemap for the above tree would be the following:

Treemap splitting by job category¶
The treemap algorithm splits the initial bounding rectangle into sub-rectangles – one per child of the root. The proportion of a child’s sub-rectangle is determined by its weight as a fraction of the total weight of its parent. For example, the treemap algorithm splits the initial rectangle from left to right into ten pieces, with each piece representing a job category. Note that pieces representing job categories with few employees are too skinny to see clearly in the treemap. Given an initial bounding rectangle with its origin at (0,0), a width of 1.0 and a height of 1.0, the resulting partition would be:
Verbose Label |
X |
Y |
Width |
Height |
|---|---|---|---|---|
|
0.000 |
0.000 |
0.053 |
1.000 |
|
0.053 |
0.000 |
0.002 |
1.000 |
|
0.054 |
0.000 |
0.010 |
1.000 |
|
0.064 |
0.000 |
0.147 |
1.000 |
|
0.211 |
0.000 |
0.001 |
1.000 |
|
0.212 |
0.000 |
0.001 |
1.000 |
|
0.212 |
0.000 |
0.575 |
1.000 |
|
0.787 |
0.000 |
0.120 |
1.000 |
|
0.907 |
0.000 |
0.003 |
1.000 |
|
0.910 |
0.000 |
0.090 |
1.000 |
Each row corresponds to a rectangle, and each rectangle is associated
with a node in the tree. In this case, the children of the tree’s root are all
leaf nodes, and that
is what we visualize on the treemap. The first column in this table identifies
the tree nodes’ verbose label (verbose_label), which in this specific
case happens to be identical to label as the tree contains only one
level beyond the root
node. The next four columns contain the components
of the rectangles rounded to three digits for clarity. Notice that 57.5%
of the initial rectangle (by width) went to Professionals, while 1.0% went
to Executive/Senior officials & Mgrs. These correspond to their relative
weights of 204025/354964 and 3536/354964.
While making tables like the one above is not part of this assignment, writing strategic print statements to display analogous data while you are initially writing and debugging your program will help you to isolate errors that are due to your generation of the rectangles, as opposed to errors drawing the rectangles you generate. We highly recommend you print out such information, and we will ask you to show us these sorts of print-outs when helping you to debug your code.
Let’s look at a tree that breaks down the data further by gender, which introduces additional complexity by having multiple levels of the tree beyond the root:
In [61]: data = treemap.load_diversity_data("data/diversity.csv")
In [62]: tree_full = tr.data_to_tree(data, ["job_category", "gender"])
In [63]: treemap.compute_internal_counts(tree_full)
Out[63]: 354964
In [64]: tree_full.print()
: 354964
│
├──Administrative support: 18792
│ │
│ ├──male: 7038
│ │
│ └──female: 11754
│
├──Craft workers: 543
│ │
│ ├──male: 511
│ │
│ └──female: 32
│
├──Executive/Senior officials & Mgrs: 3536
│ │
│ ├──male: 2738
│ │
│ └──female: 798
│
├──First/Mid officials & Mgrs: 52036
│ │
│ ├──male: 36366
│ │
│ └──female: 15670
│
├──laborers and helpers: 190
│ │
│ ├──male: 90
│ │
│ └──female: 100
│
├──operatives: 266
│ │
│ ├──male: 221
│ │
│ └──female: 45
│
├──Professionals: 204025
│ │
│ ├──male: 146371
│ │
│ └──female: 57654
│
├──Sales workers: 42615
│ │
│ ├──male: 29209
│ │
│ └──female: 13406
│
├──Service workers: 904
│ │
│ ├──male: 585
│ │
│ └──female: 319
│
└──Technicians: 32057
│
├──male: 24483
│
└──female: 7574
The treemap for this tree would look like this:

Treemap splitting by job category and gender¶
The treemap algorithm first splits the initial rectangle left to right by job category, just as for the previous tree. There is a second step, however, for this tree because it contains another level. This additional level of the tree represents the gender distribution within that job category. Notice that while the proportions for a particular job category are split the same as in the previous treemap, there is a subsequent split within each of those rectangles. That is, the rectangle representing a particular job category is then split by gender.
Pay close attention to the fact that the orientation of the split has also changed after progressing to this next level; rectangles representing gender are split (allocated) from top to bottom, rather than from left to right. As a result, the width for a particular job category for this treemap is identical to the width for that job category in the previous treemap. However, whereas the height of all nodes in the first example was 1.000, the height is distributed proportionally by gender in this second example. Assuming the initial bounding rectangle has its origin at (0,0), a width 1.0, and a height 1.0, the resulting partition would be:
Verbose Label |
X |
Y |
Width |
Height |
|---|---|---|---|---|
|
0.000 |
0.000 |
0.053 |
0.375 |
|
0.000 |
0.375 |
0.053 |
0.625 |
|
0.053 |
0.000 |
0.002 |
0.941 |
|
0.053 |
0.941 |
0.002 |
0.059 |
|
0.054 |
0.000 |
0.010 |
0.774 |
|
0.054 |
0.774 |
0.010 |
0.226 |
|
0.064 |
0.000 |
0.147 |
0.699 |
|
0.064 |
0.699 |
0.147 |
0.301 |
|
0.211 |
0.000 |
0.001 |
0.474 |
|
0.211 |
0.474 |
0.001 |
0.526 |
|
0.212 |
0.000 |
0.001 |
0.831 |
|
0.212 |
0.831 |
0.001 |
0.169 |
|
0.212 |
0.000 |
0.575 |
0.717 |
|
0.212 |
0.717 |
0.575 |
0.283 |
|
0.787 |
0.000 |
0.120 |
0.685 |
|
0.787 |
0.685 |
0.120 |
0.315 |
|
0.907 |
0.000 |
0.003 |
0.647 |
|
0.907 |
0.647 |
0.003 |
0.353 |
|
0.910 |
0.000 |
0.090 |
0.764 |
|
0.910 |
0.764 |
0.090 |
0.236 |
The above table represents the exact rectangles we would have to generate
for this treemap. Notice how we don’t generate rectangles for the first
level, e.g., we don’t generate a rectangle for all Technicians and,
instead, generate the rectangles for the specific divisions within
Technicians (Technicians: male and Technicians: female).
In fact, when we draw the Technicians: male and Technicians: female
rectangles, that encompasses the entire area that was used by Technicians
in the first example.
Finally, while this example has two levels, your code should be able to construct treemaps from trees with an arbitrarily large number of levels. The orientation of the partitions alternates between left-to-right and top-to-bottom as we move down each level of the tree. If our tree had a third level beyond these two, that third level would again have been split left-to-right. Alternating the split at each level in the tree produces a picture that is much easier to understand than one in which all the partitions have the same orientation.
For example, the following treemap visualizes a tree with three levels:

Treemap splitting by job category, gender, and race¶
Once we get to this number of levels, it can be a bit hard to visually distinguish how the splits are being done but, in this case, the rectangles representing job category (the first level of the tree beyond the root) are split left-to-right. Then, the rectangles representing gender (the second level) are split top-to-bottom. Finally, the rectangles representing race (the final level of the tree) are again split left-to-right. A better color scheme might make this treemap more readable, but we do not need to concern ourselves with that in this assignment.
Task 3¶
Your final (and most complicated) task is to complete this function in treemap.py:
def compute_rectangles(t, bounding_rec_height=1.0, bounding_rec_width=1.0):
'''
Computes the rectangles for drawing a treemap of the provided tree
Inputs:
t (Tree): a tree
bounding_rec_height, bounding_rec_width (floats): the size of
the bounding rectangle.
Returns: a list of Rectangle objects
'''
This function takes a tree and, optionally, the height and width of the initial
bounding rectangle, and returns a list of Rectangle objects.
Notice how we have already included the code to call compute_internal_counts
and compute_verbose_labels. You do not need to call them before
calling compute_rectangles.
As in Tasks 1 and 2, your code for computing the rectangles for the treemap must be recursive. Also, you may not make any assumptions about the number of levels in the tree.
Hint: compute_rectangles itself should not be recursive. Instead,
write a recursive helper function that you will call from compute_rectangles.
The implementation of this function is not too complex (our solution is 25 lines long), but figuring out the recursion can be challenging. Make sure to think through the design of the recursion following the steps we gave in class.
Testing Task 3¶
We suggest you start by testing this function informally from IPython by printing out the rectangles produced by the function. Here are some sample calls using the small dataset:
In [80]: data_small = treemap.load_diversity_data("data/diversity-small.csv")
In [81]: tree_small = tr.data_to_tree(data_small, ["company"])
In [82]: rects = treemap.compute_rectangles(tree_small)
In [83]: for r in rects:
...: print(r)
RECTANGLE 0.0000 0.0000 0.3664 1.0000 Apple
RECTANGLE 0.3664 0.0000 0.1328 1.0000 Facebook
RECTANGLE 0.4992 0.0000 0.5008 1.0000 Google
In [84]: tree_small = tr.data_to_tree(data_small, ["company", "gender"])
In [85]: rects = treemap.compute_rectangles(tree_small)
In [86]: for r in rects:
...: print(r)
RECTANGLE 0.0000 0.0000 0.3664 0.7479 Apple: male
RECTANGLE 0.0000 0.7479 0.3664 0.2521 Apple: female
RECTANGLE 0.3664 0.0000 0.1328 0.7114 Facebook: male
RECTANGLE 0.3664 0.7114 0.1328 0.2886 Facebook: female
RECTANGLE 0.4992 0.0000 0.5008 0.7667 Google: male
RECTANGLE 0.4992 0.7667 0.5008 0.2333 Google: female
And here are sample calls that correspond to the two treemaps we used when explaining the treemap algorithm:
In [96]: data = treemap.load_diversity_data("data/diversity.csv")
In [97]: tree_full = tr.data_to_tree(data, ["job_category"])
In [98]: rects = treemap.compute_rectangles(tree_full)
In [99]: for r in rects:
...: print(r)
RECTANGLE 0.0000 0.0000 0.0529 1.0000 Administrative support
RECTANGLE 0.0529 0.0000 0.0015 1.0000 Craft workers
RECTANGLE 0.0545 0.0000 0.0100 1.0000 Executive/Senior officials & Mgrs
RECTANGLE 0.0644 0.0000 0.1466 1.0000 First/Mid officials & Mgrs
RECTANGLE 0.2110 0.0000 0.0005 1.0000 laborers and helpers
RECTANGLE 0.2116 0.0000 0.0007 1.0000 operatives
RECTANGLE 0.2123 0.0000 0.5748 1.0000 Professionals
RECTANGLE 0.7871 0.0000 0.1201 1.0000 Sales workers
RECTANGLE 0.9071 0.0000 0.0025 1.0000 Service workers
RECTANGLE 0.9097 0.0000 0.0903 1.0000 Technicians
In [100]: tree_full = tr.data_to_tree(data, ["job_category", "gender"])
In [101]: rects = treemap.compute_rectangles(tree_full)
In [102]: for r in rects:
...: print(r)
RECTANGLE 0.0000 0.0000 0.0529 0.3745 Administrative support: male
RECTANGLE 0.0000 0.3745 0.0529 0.6255 Administrative support: female
RECTANGLE 0.0529 0.0000 0.0015 0.9411 Craft workers: male
RECTANGLE 0.0529 0.9411 0.0015 0.0589 Craft workers: female
RECTANGLE 0.0545 0.0000 0.0100 0.7743 Executive/Senior officials & Mgrs: male
RECTANGLE 0.0545 0.7743 0.0100 0.2257 Executive/Senior officials & Mgrs: female
RECTANGLE 0.0644 0.0000 0.1466 0.6989 First/Mid officials & Mgrs: male
RECTANGLE 0.0644 0.6989 0.1466 0.3011 First/Mid officials & Mgrs: female
RECTANGLE 0.2110 0.0000 0.0005 0.4737 laborers and helpers: male
RECTANGLE 0.2110 0.4737 0.0005 0.5263 laborers and helpers: female
RECTANGLE 0.2116 0.0000 0.0007 0.8308 operatives: male
RECTANGLE 0.2116 0.8308 0.0007 0.1692 operatives: female
RECTANGLE 0.2123 0.0000 0.5748 0.7174 Professionals: male
RECTANGLE 0.2123 0.7174 0.5748 0.2826 Professionals: female
RECTANGLE 0.7871 0.0000 0.1201 0.6854 Sales workers: male
RECTANGLE 0.7871 0.6854 0.1201 0.3146 Sales workers: female
RECTANGLE 0.9071 0.0000 0.0025 0.6471 Service workers: male
RECTANGLE 0.9071 0.6471 0.0025 0.3529 Service workers: female
RECTANGLE 0.9097 0.0000 0.0903 0.7637 Technicians: male
RECTANGLE 0.9097 0.7637 0.0903 0.2363 Technicians: female
Once you are confident that you’re producing the correct rectangles,
you can start visualizing them using the draw_rectangles function:
In [87]: drawing.draw_rectangles(rects)
To run the automated tests for this task only with the small dataset,
you can run the following:
$ py.test -x -v -k "rectangles and small"
To run all the Task 1 tests (with both the small and full datasets), run this:
$ py.test -x -v -k rectangles
Putting it all together¶
Once you have completed all the tasks, you will be able to easily generate any treemap you want from the command-line. In particular, you can run the following:
python3 diversity.py -i data/diversity.csv -c CATEGORIES_LIST
Where CATEGORIES_LIST is a comma-separated list of categories to
use when dividing the treemap. This corresponds to the hierarchy
parameter we pass to data_to_tree.
Here are some examples and the expected treemap. Take into account that
running diversity.py will open a new window with the treemap;
you will need to close that window before you can return to the
command line.
NOTE: If you are passing all the tests, do not worry if the produced treemaps do not match ours exactly! Your completeness grade will depend on the result of the tests, not on the exact graphics you produce.
python3 treemap.py data/diversity.csv -c job_category,gender

Treemap of gender diversity by job category¶
python3 treemap.py data/diversity.csv -c job_category,gender,race

Treemap of gender and racial diversity by job category¶
python3 treemap.py data/diversity.csv -c company,gender,race

Treemap of gender and racial diversity by company¶
Additionally, you can use a -p parameter to specify labels to prune:
python3 treemap.py data/diversity.csv -c company,race,gender -p Asian,White

A view of the non-white and non-asian Silicon Valley workforce¶
python3 treemap.py data/diversity.csv -c company,gender,race -p "Adobe,Airbnb,Apple,Cisco,eBay,Facebook,Google,HP Inc.,HPE,Intel,Intuit,LinkedIn,Lyft,Nvidia,Salesforce,Square,Twitter,Uber"

Gender and racial diversity of companies with fewer than 1,000 employees¶
Grading¶
Programming assignments will be graded according to a general rubric. Specifically, we will assign points for completeness, correctness, design, and style. (For more details on the categories, see our PA Rubric page.)
The exact weights for each category will vary from one assignment to another. For this assignment, the weights will be:
Completeness: 50%
Correctness: 20%
Design: 15%
Style: 15%
In this assignment, the Design grade will largely be based on how you designed your recursive functions.
Please note that if you do not recursion in a given task, you can expect a considerable deduction in both the Correctness and Design portions of the rubric. If you do not use recursion at all in your code, you will receive a zero in both Correctness and Design.
Obtaining your test score¶
Like previous assignments, you can obtain your test score by running py.test
followed by ../common/grader.py.
Continuous Integration¶
Continuous Integration (CI) is available for this assignment. For more details, please see our Continuous Integration page. We strongly encourage you to use CI in this assignment.
Submission¶
To submit your assignment, make sure that you have:
put your name at the top of your file,
added, committed, and pushed
treemap.pyto the git server, andrun the chisubmit submission command.
Here are the relevant commands to run on the Linux command-line.
(Remember to leave out the $ prompt when you type the command.)
$ chisubmit student assignment register pa7
$ git add treemap.py
$ git commit -m"Final version of PA #7 ready for submission"
$ git push
$ chisubmit student assignment submit pa7
Remember to push your code to the server early and often! Also, remember that you can submit as many times as you like before the deadline.
Acknowledgments: Gordon Kindlmann originally recommended drawing treemaps as good topic for an assignment.