An Auto-Completing Keyboard using Tries¶
Due: Friday, January 22nd at 4pm
The purpose of this assignment is to give you more practice working with recursive data structures and classes. You must work alone on this assignment.
Introduction¶
Chances are pretty high that you have used a smart phone with a touch-screen keyboard. As you type, the phone is trying to guess what you’re typing in the background.
It is very likely that if you are typing a specific word, the phone may show a suggested completion on the screen and give you the opportunity to accept or reject it. For instance, if you start to type “aardv” and if you are using English language, it must be “aardvark” and the phone suggests this word.
Alternatively, if the letters you are typing do not appear to belong to a word, or at least not to a common word, then the phone recognizes this situation, too. It might present a graphical cue that the word is misspelled. Or, it might check whether there are words in the dictionary whose sequence of keystrokes are very close to the ones you entered on the keyboard (for instance, “dit” is, key-for-key, close to “for”, so perhaps that is what you meant).
How does the phone manage the information it needs to make these decisions? Clearly, it has a built-in dictionary. But how does it search that dictionary efficiently as you are typing?
We implemented a class named EnglishDictionary that provides a
sensible interface for applications that want to include word lookup or
auto-completion. Unfortunately, our implementation, which is
list-based, is very slow. Your task is to replace our implementation
with a more efficient implementation that provides exactly the same
interface but uses a data structure, known as a trie, that is
tailor-made for this type of application.
Representing English Language Dictionaries¶
The EnglishDictionary class provides a constructor and a handful
of useful methods. The constructor takes the name of a file that
contains one word per line and loads the words into a data structure.
The method:
def is_word(self, w)
determines whether a particular string w is a complete word in the
dictionary. (Note: we use the word dictionary in this assignment to
refer to instances of this class and not to the Python data structure
of the same name unless otherwise noted.) The method:
def get_completions(self, prefix)
returns a list of all of the suffixes of a specified prefix which, together, represent a word contained in the dictionary. Specifically, the function should return a list containing just the suffixes, not the entire word. This function should return the empty list if the dictionary does not include any words that start with the prefix.
Finally, the method:
def num_completions(self, prefix)
returns the number of full words beginning with the specified prefix in the dictionary. IMPORTANT: Do not implement this function by simply taking the length of the value returned by the previous method.
Getting started¶
We have seeded your repository with a directory for this assignment. To pick it up, change to your cmsc12200-win-21-username directory (where the string username should be replaced with your username) and then run the command: git pull upstream master. You should also run git pull to make sure your local copy of your repository is in sync with the server.
Here is a description of the contents of the directory:
english_dictionary.py– you will complete theEnglishDictionaryandTrieNodeclasses in this file.english_dictionary_list.py– a list implementation of theEnglishDictionaryclass.autocorrect_shell.py– user-interface implementation.web2– a copy of the words from the 1934 edition of Merriam-Webster’s Dictionary.five– a simple list of words with only the five words shown in the example diagram below.
The file autocorrect_shell.py contains code for a simple user
interface that uses EnglishDictionary to implement a text-based
interface to write a message with auto-complete features. You can run
the interface using our list-based implementation using this command:
$ python3 english_dictionary_list.py WORDS_FILE
Where WORDS_FILE is a file with words (one per line) to be loaded into the dictionary. We provide two files:
A small example list of words named
fivewith only the five words in the example diagram below.A large list of words,
web2, based on the 1934 version of Merriam-Webster’s Dictionary, for you to use once your implementation is complete. Because this real-world dictionary has hundreds of thousands of words, you should not be alarmed if it takes ten seconds or more to load it in.
We strongly encourage you to play around with this version before you start writing your own solution. Important: remember that you need to specify a particular word file, such as:
$ python3 english_dictionary_list.py five
The user interface starts with a prompt for you to write a word. For each character you write, the functions described above are called to determine if there are matches in the dictionary for the partial word you have written. If there are no matches, our code writes out a message to that effect. If there is one match, our code completes the word based on the match you provide. If there is more than one match, then our code continues to wait for further characters to be entered. If you press space before an auto-completion, we leave the word as you typed it and allow you to start entering the next word. If you press the tab key in the middle of a word, then we print out a list of possible completions based on the results of calling get_completions. However, if there are more than ten completions, we only print a message to that effect, to avoid printing an excessive amount of information to the screen.
A better data structure: Tries¶
Our implementation of the EnglishDictionary class, which uses
lists, is very slow. If we test for duplicate words as we add words
to the list, constructing an instance from the words in web2 takes
nearly 10 minutes on linux1.cs.uchicago.edu. Similarly, simply
counting the number of completions for the string “ar” took more than
40 milliseconds.
Fortunately, there is a much better data structure, known as a trie, that can be used for this purpose. A trie represents sequences (in this case, of letters) and is suitable for determining whether a partial sequence is the prefix to at least one entry. A trie can tell us instantly if a sequence is a “dead end” that does not have any valid completions; and when a sequence does have completions, we can count them and enumerate them in a straightforward fashion.
We will start by describing a trie conceptually. A trie is a recursive data structure, that is, a trie is made by taking smaller tries and combining them.
A trie starts with a node. A node contains information about the first k letters of a sequence, as well as links to sub-tries. These links are labeled by the next letter in the sequence.
As we consider a particular sequence, we start at the beginning (root) node, then follow the link for the first letter in the sequence. This step takes us to a new node. At this node, we can check the information stored to determine statistics about the sequence so far. We will have access to a “count”, which tells us how many words exist that begin with that sequence. We can also check to see if there is a word that ends at that letter. As an example, if the first letter is “a”, then we start at the initial node and follow the link to the node representing all words that begin with “a”. We will find a count indicating how many such words exist, and an indication that “a” itself is indeed a word even without adding additional characters.
As another example, the figure below shows the complete trie for a language consisting only of the words “a”, “an”, “and”, “are”, and “bee”.
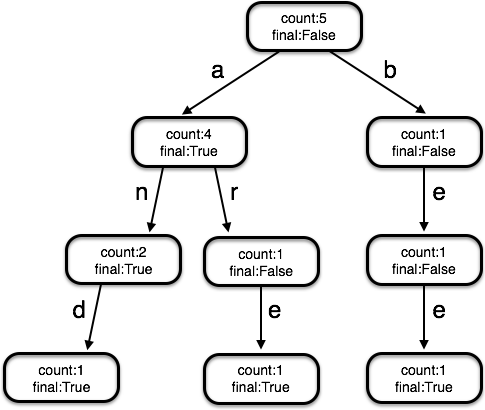
Now, let’s talk about how to accomplish useful tasks using a trie.
Getting information for a sequence¶
If we have a sequence of letters corresponding to the beginning of a word, we can traverse the trie to find the information corresponding to that sequence.
From the root, we follow the link labeled with the first letter in the sequence to get to another node. From there, we follow the link labeled with the second letter of the sequence to get to yet another node. We continue following links for each successive letter in the sequence. We are now at a node representing that sequence as a prefix to words. At that node will be a count, indicating how many words begin with that prefix; also, there will be a flag indicating whether the sequence itself is a word.
If along the way, we were to discover that the link for the next letter in our sequence does not exist, then the sequence is not a valid prefix for any words, and we could stop at that point and conclude that the word is misspelled (or otherwise not in our dictionary). For example, given the word “arctic”, we would stop and report failure after following the prefix “ar”, because there is no link labeled “c” out of the node reached by starting at the root, following the link labeled “a” and then the link labeled “r”.
Each time we follow a link to reach a new node, we arrive at a node while we are holding on to a list of letters in our sequence yet to be followed. Because this situation is very similar to the situation we are in when we begin traversing the structure (we have the entire sequence of letters yet to be considered, and are at the starting node), the problem of writing the traversal code naturally lends itself to recursion.
Completing a sequence¶
Once we have arrived at the node corresponding to the entire prefix, we can generate all possible completions of that sequence into words.
We do this by traversing every link out of the node corresponding to our prefix (thus considering all possible first letters in a completion), and every link from each of those nodes (all possible second letters), and so on, until there are no more links to follow. Every time we traverse a link to reach another node, we keep track of the sequence of letters we needed to add to our prefix to arrive at that node. Every time we encounter a node marked final (in other words, one that corresponds to a full word), we add the sequence of letters used to arrive at that node to our list of possible completions.
The traversal of the nodes and links in this scenario again lends itself to a recursive implementation.
Building a trie from a list of words¶
We can build a trie from a list of words one word at a time.
After creating an initial node corresponding to the empty prefix, we add each individual word according to the following process.
Starting at the initial node, we follow the link for the first letter in the word. If it does not exist, we create that link and the destination node. We then repeat this process for each subsequent letter until we have consumed all of the letters in the word. At the final node, we mark the node as final, indicating that a complete word corresponds to that prefix. At every node we visit along the way, we also increment the count of words with that prefix by one.
As with the other two operations, the repeated traversal of nodes and links lends itself to recursive programming.
Task: implementing Tries¶
Your first task is to complete the TrieNode class. We recommend
using three attributes: one for the count at the node, one that is set
to True if the node represents a “final” sequence, that is, the
completion of a word, and one that holds a Python dictionary that maps
letters to child TrieNodes (yes, this time we mean the built-in
Python dictionary).
We have provided part of a skeleton for this class that includes the
constructor and a method, named add_word that should add a word to
the trie. You are on your own for deciding what other methods to
include in the class. We encourage you to think carefully about the
operations that are needed by EnglishDictionary when deciding which
methods to add to this class. For credit, and as suggested by the descriptions of trie operations above, use recursion to navigate through the trie.
Our implementation of this class has four methods, including the constructor, and is under 30 lines of code (not including header comments).
We strongly encourage you to test your trie implementation before you
move on to the next task. You can use the EnglishDictionary
constructor to build a trie like the one depicted above using:
ed5 = english_dictionary.EnglishDictionary("five")
and then test the rest of your methods by hand using the root of the
constructed trie: ed5.words.
Task: implementing the English dictionary class¶
Once your TrieNode class is ready, your next task is to complete
the is_word, get_completions, and get_num_completions
methods in the EnglishDictionary class. We have already
implemented the constructor.
We remind you that you should not compute the number of completions
simply as len(self.get_completions(prefix)).
Please note that you may need to rethink your design of TrieNode a
few times as you work on implementing the methods in
class EnglishDictionary. In particular, make sure you think about
ways to avoid writing very similar code for different operations.
It should not be a cause for concern if the code in this class relies heavily on the methods you wrote earlier.
Using the auto-complete shell to test your code¶
You can run the following command to use the provided user interface with your implementation:
$ python3 english_dictionary.py WORDS_FILE
Again, please keep in mind that you need to specify a particular file, such as five or web2, rather than the placeholder WORDS_FILE.
If your functions are implemented correctly, it should be possible to
type the following sentence and, as you do, the program should
auto-complete the letters written in parentheses on its own (note: you
have to use the web2 file for this):
The aardv(ark) had a multifacet(ed) similarit(y) to native species of phytopl(ankton) that permeate the maritim(e) region of predominatel(y) equatoriall(y) situated nations
There are no words that start with ‘nations’
The word “nations” should register as misspelled, even though it is not, because Webster’s Dictionary does not include plurals. The word “permeate” and the word “situated” should be recognized as complete words and result in a space being inserted for you, though no letters will be completed by the program (Webster’s Dictionary does not have words starting with these prefixes that are longer.)
As a further test, if you type the letters “antic” and then tab, you should be told that there are 145 completions. If you then continue typing to yield the partial word “anticip” and press tab again, you should receive the following suggested completions (in any order):
anticipatable
anticipate
anticipation
anticipative
anticipatively
anticipatorily
anticipator
anticipatory
anticipant
Submission¶
To submit your assignment, make sure that you have:
put your name at the top of your files,
registered for the assignment using chisubmit,
added, committed, and pushed your code to the git server, and
run the chisubmit submission command.
$ chisubmit student assignment register pa1
$ git add english_dictionary.py
$ git commit -m "final version of PA #1 ready for submission"
$ git push
$ chisubmit student assignment submit pa1
Make sure, before confirming, that the version that chisubmit says you are submitting is actually the version you want graded. This step is designed to help you check that the commit message and timestamp match your intended submission, and you are responsible for carefully checking this before proceeding. If the timestamp indicates an earlier version, then something has not made it to the server successfully, and you must cancel and investigate.
Acknowledgments: This assignment was designed by Matthew Wachs and revised by Anne Rogers.