Team Tutorial #4: Classes and Objects¶
For instructions on how to get started on these tutorials, please see Team Tutorial #1.
This tutorial is divided into two parts. In Part 1, we will extend the Point class introduced in lecture and implement a Library class to work with some data from the Hawaii State Public Library. In Part 2, we will add some functionality to the Divvy classes we saw in the lectures.
In this tutorial, you will have a chance to:
Create instances of a class from the interpreter
Apply methods to an instance of a class from the interpreter
Add methods to an existing class
Define a class and its methods from scratch
Contribute new methods to a class that is composed from other classes.
Getting started¶
If this is your first time working through a Team Tutorial, please see the “Getting started” section of Team Tutorial #1 to set up your Team Tutorials repository.
To get the files for this tutorial, set an variable
GITHUB_USERNAME with your GitHub username, navigate to your Team
Tutorials repository, and then pull the new material from the
upstream repository:
cd ~/capp30121
cd team-tutorials-$GITHUB_USERNAME
git pull upstream main
You will find the files you need in the tt4 directory.
Part 1: Working with Objects¶
The goal of this part of the tutorial is to understand how objects work. In Team Tutorial #2, you wrote some functions of your own and got some practice calling them in order to create larger programs that were made possible through the composition of those functions. In this tutorial, you will take that idea a step further by using objects to organize and compose data.
Python is an object-oriented language, which means that everything in Python is really a structure called an object. So, for example, when we create a dictionary:
In [1] d = {"foo": 42, "bar": 37}
What we’re really doing is creating an instance of the dict class
which we store in a variable called d. The “type of an object” is
called its class. So, when we refer to “the dict class” we refer
to the specification of a datatype that is used to contain dictionaries. In fact, we can also create a dictionary like this:
In [2] d = dict([("foo", 42), ("bar", 37)])
Or an empty dictionary like this:
In [3] d = dict()
In lecture, we’ve referred to some data types (like int
and float as “primitive data types” that specify a domain of values
(like integers, real numbers, boolean values, etc.). In Python, these data types are
actually also objects, even if we don’t tend to think of them as such (in
fact, some other programming languages, like Java, also handle primitive data types
as non-object types). For example, if you create a float variable:
In [4] x = 0.33
Variable x is actually an instance of Python’s float class, which has
a few handy methods, like as_integer_ratio, which returns the floating
point number as a numerator/denominator tuple:
In [5] x = 0.25
In [6] x.as_integer_ratio()
Out[6](1, 4)
Feel free to play around with this type a bit. What other methods are available?
Point class¶
In lecture, we introduced the Point class shown below.
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def distance_to_origin(self):
return math.sqrt(self.x**2 + self.y**2)
This class has a constructor, two attributes (x and y), and one
method called distance_to_origin which returns the distance
betweeen the point and the origin.
We can store the Point class in a module called point.py and use it
in IPython by importing the module, creating an instance of Point,
and calling the distance_to_origin method on that instance.
In [1]: import point
In [2]: p0 = point.Point(-1, 1)
In [3]: p0.x
Out[3]: -1
In [4]: p0.y
Out[4]: 1
In [5]: p0.distance_to_origin()
Out[5]: 1.4142135623730951
In this section, you’ll add two methods to the Point class. Start by
opening up point.py in VSCode and start an IPython session for
testing and experimentation.
Polar coordinates can be used as an alternative to the familiar Cartesian coordinate system. Polar coordinates are determined by a distance from a reference point (\(r\)) and an angle (\(\theta\)) from a reference direction. Given the Cartesian coordinates (x, y), we can compute Polar coordinates using the following formulas:
Complete the to_polar method in the Point class with the following header.
For this problem, you can assume that \(x > 0\).
def to_polar(self):
'''
Compute the polar coordinates
Returns: radial coordinate, angular coordinate
in degrees (tuple)
'''
You will need to use the sqrt function from the math module, as well
as two others:
math.atan: returns the inverse tangent of a number in randians,math.degrees: converts an angle from radians to degrees.
You can test your method by creating an instance of the Point class and calling your method on the instance.
In [6]: p1 = point.Point(1, 1)
In [7]: p1.to_polar()
Out[7]: (1.4142135623730951, 45.0)
In Team Tutorial #2, you wrote a function called dist to calculate
the distance between two points (x1, y1) and (x2, y2) using the
formula:
Your function probably looked something like this:
def dist(p1, p2):
(x1, y1) = p1
(x2, y2) = p2
return math.sqrt((x1 - x2)*(x1 - x2) + (y1 - y2)*(y1 - y2))
And you might’ve used it in IPython like this:
In [8]: p3 = (1, 2)
In [9]: p4 = (1, 3)
In [10]: dist(p3, p4)
Out[10]: 1.0
Now you will implement the same computation in an object-oriented fashion.
Complete the Point method called distance in
with the header:
def distance(self, other):
'''
Calculate the distance between two points
Input:
other: (Point) the other point
Returns: distance (float)
'''
This method returns the distance between the calling Point instance
(self) and another Point instance (other). You can call your function from
IPython like this:
In [11]: p5 = point.Point(0, 0)
In [12]: p6 = point.Point(1, 1)
In [13]: p5.distance(p6)
Out[13]: 1.4142135623730951
In [14]: p6.distance(p5)
Out[14]: 1.4142135623730951
Library class¶
In this exercise, you will be using data from the Statistics by type of media in Hawaii State Public Libraries for 2011. For each Hawaiian public library, the Hawaii State Public Library System keeps track of the following:
location of the branch (a Hawaiian island),
name of the branch,
number of references,
number books,
number of microform documents,
among some other things. For simplicity, we will assume that a library only contains references, books, and microform documents in its circulation.
In this exercise, you will implement a Library class to organize the data
from this dataset along with some functions to work with the data.
Start by opening up library.py in VSCode and add the following to
the Library class.
Write a constructor for the Library class. Your constructor should take six parameters (including
self) and initialize five attributes. It’s important for our helper function that you follow this exact naming and ordering.islandnamereferencebookmicroform
Write a method called
total_circulationthat returns the total number of items in circulation at the library. The circulation of a library is the number of references, books, and microform documents. This method will have only one parameter,self.Write a method called
has_microform_cataloguethat returnsTrueif a library has any microform documents andFalseotherwise. This method will also only haveselfhas a parameter.
You can test your implementation by creating a Library object in IPython and calling your methods on your object.
In [1]: import library
In [2]: lib = library.Library("Oahu", "Kaneohe", 6906, 109880, 313)
In [3]: lib.island
Out[3]: 'Oahu'
In [4]: lib.name
Out[4]: 'Kaneohe'
In [5]: lib.reference
Out[5]: 6906
In [6]: lib.book
Out[6]: 109880
In [7]: lib.microform
Out[7]: 313
In [8]: lib.total_circulation()
Out[8]: 117099
In [9]: lib.has_microform_catalogue()
Out[9]: True
We have included a utility module called util.py that creates an instance
of your Library class for each Hawaiian public library included in
the dataset. The Library objects are stored in a list called HI_LCS_2011,
which you can utilize from IPython.
In [10]: import util
In [11]: len(util.HI_LCS_2011)
Out[11]: 51
In this task, you will complete the following functions to answer questions about
the library data. Both functions take as input a list of Library objects
(such as HI_LCS_2011). Be sure to use your Library class methods
to complete the functions.
Write a function called
branch_with_biggest_circulationthat takes a list of Library objects as an argument and finds the name of the branch with the biggest number of items in circulation.Write a function called
percentage_with_microformthat takes a list of Library objects as an argument and computes the percentage of branches that have a microform catalogue.
Finally, test your functions from IPython.
In [12]: library.branch_with_biggest_circulation(util.HI_LCS_2011)
Out[12]: 'Hawaii State'
In [13]: library.percentage_with_microform(util.HI_LCS_2011)
Out[13]: 7.8431372549019605
Unsurprisingly, Hawaii State has a large collection and few branches still have microform catalogues.
When Finished with Part 1¶
When you are finished with this part of the tutorial, please check in
your work by running these commands from the linux command line
(assuming you are inside the tt4 directory):
git add point.py
git add library.py
git commit -m "Finished with tt4, part1"
git push
Following these steps will help ensure your repository is in a clean state and that your work is saved to GitHub.
Part 2: Class Composition¶
In this part of the tutorial, we will explore how to use multiple classes together using composition relationships between classes. To do so, we will use several classes that model information about the Divvy bike-sharing program.
Working with the Divvy Data¶
As you probably know, Divvy is Chicago’s enormously popular bike sharing system. In 2014, Divvy published (anonymized) data on all the Divvy bicycle trips taken in 2013 as part of the 2013 Divvy Data Challenge). This dataset, as well as more recent ones, are openly available on the Divvy Data page.
The original dataset contains two files: one with information about each Divvy station, and one with information about each Divvy trip.
In this part of the tutorial, we will be using four classes that model the Divvy dataset:
Location: A class representing a geographic location.DivvyStation: A class representing an individual Divvy station.DivvyTrip: A class representing an individual Divvy trip.DivvyData: A class representing the entire dataset, which includes a list of stations and a list of trips.
An important aspect of object orientation is the ability to create
relationships between different classes, to model real-world
relationships. For example, a Divvy trip has an origin station and a
destination station. Instead of trying to pack all the information
about the stations in the DivvyTrip class, we instead have a
separate DivvyStation class that is used to represent individual
stations. The DivvyTrip class then only needs to have two
attributes of type DivvyStation: one for the origin station and
one for the destination station.
These relations are referred as composition relationships, because they allow us to define a class that is composed of other classes. A useful way to think of these kind of relationships is that, if you can describe the relationship as “has a” (e.g., “A DivvyStation has a Location”), it is probably a composition relationship.
All the composition relations between the Divvy classes are summarized in the following figure:
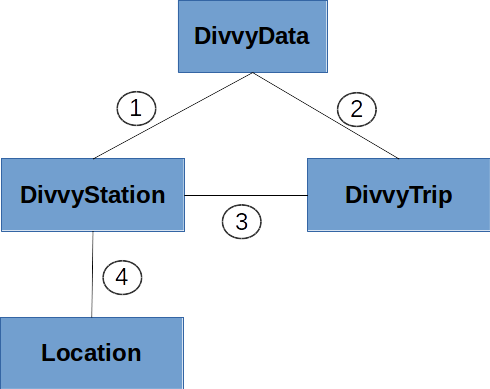
1,2. The DivvyData class represents the entire Divvy dataset, so it
contains (1) a dictionary that maps station identifiers to DivvyStation
objects, and (2) a list of DivvyTrip objects.
3. As discussed above, a DivvyTrip has two DivvyStation
objects associated with it. This relationship is implemented simply by setting
two attributes, from_station and to_station in the
DivvyStation constructor.
4. Finally, each Divvy station has a location, which we represent
using an instance of the Location class. Again, this is done
simply setting an attribute, location to a Location object
in the DivvyStation constructor.
The DivvyData class also has a bikeids attribute with a set of all the bike
identifiers in the dataset. This is not a composition relationship, but it is
something you may find useful in some of this tutorial’s tasks.
For more details on the Divvy classes, please read the Composition section of the textbook’s chapter on Classes and Objects.
Before you get started¶
Before you get started, you will need to download the Divvy dataset files.
To do so, go into the tt4/data directory in your terminal, and run the
following:
./get_files.sh
This will download the files; if the download is successful, you should see this at the end of the command’s output:
Extracting Divvy data...
divvy_2013_stations.csv
divvy_2013_trips.csv
divvy_2013_trips_medium.csv
divvy_2013_trips_small.csv
divvy_2013_trips_tiny.csv
We have provided the full dataset (divvy_2013_trips.csv) but also some
smaller files that will take less time to load.
Next, you will want to have an IPython session open. Make sure you start
IPython from the tt4 directory, and that you load the autoreload
extension, and then import the divvy module:
In [1]: %load_ext autoreload
In [2]: %autoreload 2
In [3]: import divvy
Computing the total distance of each bike¶
We are going to start by adding a simple method to the DivvyData class,
which is contained in the divvy.py file in your tt4 directory.
You’ll see this class already has methods to compute the total distance
of all the trips (get_total_distance), and the total duration of all
the trips (get_total_duration). Make sure you understand how these
methods work before continuing!
You are going to add a new method to the DivvyData class that computes, for every bike in the Divvy dataset, the sum of the duration of all the trips taken by that bike:
def get_bike_times(self):
"""
Computes, for every bike in the Divvy dataset, the sum of the
duration of all the trips taken by that bike.
Returns a dictionary mapping bike identifiers (integer) to
a duration in seconds (integer)
"""
To implement this method, you will need to access the bikeid attribute
of the DivvyTrip objects in the DivvyData class. This attribute contains
the identifier of the bike used for that trip.
You can test your implementation from IPython by creating a DivvyData object with our “tiny” dataset, and then testing a few bikes individually. For example:
In [5]: data = divvy.DivvyData("data/divvy_2013_stations.csv",
...: "data/divvy_2013_trips_tiny.csv")
...:
In [6]: dt = data.get_bike_times()
In [7]: dt[27]
Out[7]: 10105
In [8]: dt[44]
Out[8]: 1852
Later on, we’ll see a more thorough way to test your implementation. However, if your implementation works with the examples above, just move on to the next task for now.
Computing the number of times a bike has been moved¶
If you’ve lived in Chicago long enough, you may have spotted the Divvy vans that occasionally come to a Divvy station to place bikes on the station’s dock if the station is running low on bikes. Not just that, they’ll also take bikes away if the station has too many bikes and seems to be underutilized.
So, you will sometimes see trips like this in the dataset:
Trip #1234: Customer A took Bike 44 from station 10 to station 20
Trip #1235: Customer B took Bike 44 from station 20 to station 30
Trip #1236: Customer C took Bike 44 from station 50 to station 70
This means that the bike was moved by a Divvy van from station 30 to station 50!
You will add a method to the DivvyData class that finds any such movements for all the bikes in the dataset:
def get_bike_movements(self):
"""
Returns a dictionary mapping bike identifiers (integer)
to a list of tuples, where each tuple represents that bike
being moved from one station to another.
Each tuple contains three values: the station the bike was
moved from (DivvyStation object), the station the bike was
moved to (DivvyStation object), and the difference in capacity
between the two stations (more specifically, the capacity
of the station the bike was moved to minus the capacity
of the station the bike was moved from). Note that this
will be an integer that can be either positive or negative.
Note that the dictionary must also include entries for
the bikes that have not been moved at all (those entries
will just map to an empty list)
"""
To implement this method, you will need to access the dpcapacity
attribute of the DivvyStation objects. You will also want to
use the bikeids attribute of DivvyData. Finally,
take into account that the trips attribute in DivvyData
has the trips sorted by their start time.
You can test your implementation from IPython using the data
object we created earlier:
In [11]: bm = data.get_bike_movements()
In [13]: bm[409]
Out[13]:
[(<DivvyStation 85: Michigan Ave & Oak St>,
<DivvyStation 350: Ashland Ave & Chicago Ave>,
0)]
Notice how the DivvyStation objects are shown using the
string representation returned by DivvyStation’s __repr__
method.
If you print the entire bm dictionary, you should actually see
that none of the other bikes have any movements. Remember we loaded a
“tiny” subset of the full dataset, so this is not unexpected.
Testing your Divvy methods more thoroughly¶
As part of the divvy.py file, we have included some code that uses
these two methods to answer these questions:
What is the average amount of time a bike is used?
What is the most used bike in the Divvy system?
What is the average number of times a bike is moved?
Do vans tend to move bikes from high capacity stations to low capacity stations, from low to high, or neither?
Once you’ve implemented the two methods specified above, just run the divvy.py
file from the terminal as follows:
python3 divvy.py data/divvy_2013_stations.csv data/divvy_2013_trips_medium.csv
Notice how we’re using our “medium”-sized dataset for this. If you implemented the methods correctly, the output should end with this:
The average total usage of a bike is 1d 8h 0m 39s
The most used bike is 444, used a total of 3d 17h 41m 10s
The average number of times a bike was moved was 16.17
On average, a bike is moved to a station with 1.05 more docks
(Standard deviation: 10.29)
If your code works with the medium data set, try running it with the full dataset:
python3 divvy.py data/divvy_2013_stations.csv data/divvy_2013_trips.csv
Please note that this will take a few seconds to run. The output should end with the following:
The average total usage of a bike is 3d 18h 36m 38s
The most used bike is 199, used a total of 9d 11h 30m 17s
The average number of times a bike was moved was 122.30
On average, a bike is moved to a station with 0.12 more docks
(Standard deviation: 9.28)
These results are interesting, but don’t forget to check out the code that
produces them! You can find it towards the bottom of the divvy.py file.
When Finished with Part 2¶
When you are finished with this part of the tutorial, run the
following commands from the linux command-line inside of your tt4
directory:
git add divvy.py
git commit -m "Finished with tt4, part2"
git push
Again, following these steps will help ensure your repository is in a clean state and that your work is saved to GitHub.