Homework #2¶
Due: Thursday, October 12th at 11:59pm
This homework is intended to serve as an introduction to using atomic operations and importance of understanding the architecture of the parallel hardware a parallel application is running on.
Getting started¶
For each assignment, a Git repository will be created for you on GitHub. However, before that repository can be created for you, you need to have a GitHub account. If you do not yet have one, you can get an account here: https://github.com/join.
To actually get your private repository, you will need this invitation URL:
When you click on an invitation URL, you will have to complete the following steps:
You will need to select your CNetID from a list. This will allow us to know what student is associated with each GitHub account. This step is only done for the very first invitation you accept.
Note
If you are on the waiting list for this course you will not have a repository made for you until you are admitted into the course. I will post the starter code on Ed so you can work on the assignment until you are admitted into the course.
You must click “Accept this assignment” or your repository will not actually be created.
After accepting the assignment, Github will take a few minutes to create your repository. You should receive an email from Github when your repository is ready. Normally, it’s ready within seconds and you can just refresh the page.
- You now need to clone your repository (i.e., download it to your machine).
Make sure you’ve set up SSH access on your GitHub account.
For each repository, you will need to get the SSH URL of the repository. To get this URL, log into GitHub and navigate to your project repository (take into account that you will have a different repository per project). Then, click on the green “Code” button, and make sure the “SSH” tab is selected. Your repository URL should look something like this: git@github.com:mpcs52060-spr22/hw2-GITHUB-USERNAME.git.
If you do not know how to use
git cloneto clone your repository then follow this guide that Github provides: Cloning a Repository
If you run into any issues, or need us to make any manual adjustments to your registration, please let us know via Ed Discussion.
Short Answer Questions¶
Each assignment may include a section dedicated to answering a few short answer questions. Please turn in a readable text file named saqs (e.g., saqs.pdf). Store this file inside the hw2/saqs directory. You will place your answers to the following questions in this document. The file is not required to be a PDF but any text document that is easy to open is fine.
Please do not ask questions on Ed or during office hours explaining your answer to SAQs to determine if it is correct or almost correct. Those types of questions will not be answered. This is what we are grading you on. However, you can ask questions related to the concepts you want to use to answer your question or to clarify the understanding of the question.
SAQ 1¶
Consider the following change to the transfer function from the m2/account1/account.go file
func transfer(flag *int64, transaction *Transaction) {
from := transaction.From
to := transaction.To
amount := transaction.amount
// Question: Is this okay to do? with having the atomics happen inside the the if-statement
if from.balance >= amount {
atomic.AddInt64(&(from.balance), -amount)
atomic.AddInt64(&(to.balance), amount)
}
}
Question: Would the program still produce deterministic results with having the atomics happen inside the the if-statement? Explain your answer.
SAQ 2¶
For this problem, assume there are two cores (Core A and Core B) that have their own private caches. There are no other caches in this system. Currently, there is a slice (myslice) that is currently stored in main memory and not in any cache.
Note
The elements of a slice are adjacent to each other in memory.
Assuming that a single cache line can hold the entire contents of myslice, then the following steps happen:
Core A reads in
myslice[1].Core B reads in
myslice[2].Core B writes in
myslice[3] = 5.Core A reads in
myslice[4].
For this problem do the following:
Fill in the table below with a MESI protocol state, based on the steps above. You will base this on the cache line that contains the
myslicevariable. If a cache does not include the cache line then leave that cell empty.For each step, provide an explanation on why you chose that specific MESI protocol state for the cache line in Core A and B.
Step |
Cache Line in Core A |
Cache Line in Core B |
1 |
||
2 |
||
3 |
||
4 |
SAQ 3¶
Consider the following:
My program has both a sequential and parallel implementation. My sequential program finishes executing in 360 seconds. My parallel version when spawning two threads finishes executing in 180 seconds, and with three threads it finishes in 120 seconds.
Claim: If I spawn 100 threads then it will always be faster than spawning two or three threads.
Based on the lectures, is the Claim statement true? Explain.
Programming Questions¶
For this assignment you are only allowed to use the following Go concurrent constructs:
gostatementsync/atomicpackage. You may use any of the atomic operations.sync.WaitGroupand its associated methods.
As the course progresses, you will be able to use other constructs provided by Go such as channels, conditional variables, mutexes, etc. I want you to learn the basics and build up from there. This way you’ll have a good picture of how parallel programs and their constructs are built from each other. If you are unsure about whether you are able to use a language feature then please ask on Ed before using it.
Critical Sections & Atomics¶
Recall from lecture the fix for the data race in the transfer function (i.e., m2/acount1/account0.go):
func transfer(flag *int64, transaction *Transaction) {
from := transaction.From
to := transaction.To
amount := transaction.amount
for !atomic.CompareAndSwapInt64(flag, 0, 1) {
}
if from.balance >= amount {
from.balance -= amount
to.balance += amount
}
atomic.StoreInt64(flag, 0)
}
Here we use a flag variable to represent the address for our atomic operation. This flag argument can only hold two values 0 or 1. We will use this argument to tell goroutines when they can enter into the critical section.
Assume we have spawned off 4 goroutines and they all reach the for loop at the same time. The CompareAndSwapInt32 is an atomic operation that atomically looks at the memory address given (i.e., &flag) and checks if the value is equal to the second argument (i.e., 0). If the value is equal to the second argument then it will update value to be equal to the third argument (i.e., 1) and return true; otherwise, if it returns false. Thus, only one goroutine will succeed in updating the flag to be 1 since they are all performing the atomic operation sequentially; therefore, those who fail (i.e., when CompareAndSwapInt32 returns false) will loop until it’s there turn to set the flag to 1. The goroutines that was successful in updating the flag to 1 now enters into the critical section and can safely update any shared variable without using atomic operations because it’s the only one in the critical section. Before the thread leaves the critical section, it needs to tell all waiting goroutines that one of them can now enter into the critical section. The exiting goroutine can use the StoreInt32 operation to reset the flag back to zero to allow another goroutine into the critical section. Thus, 0 means no goroutine is in the critical section and 1 means that a goroutine is in the critical section and all others must wait.
Static Task Decomposition¶
For problems 1 and 3, you will be implementing your first parallel programs in the course. Each goroutine will need to perform a certain amount of work to complete. But how should the work be distributed to each goroutine? For this assignment, we will look at our first parallel task distribution technique, which equally distributes the amount of work to each goroutine. Recall the crawler example from module 1,
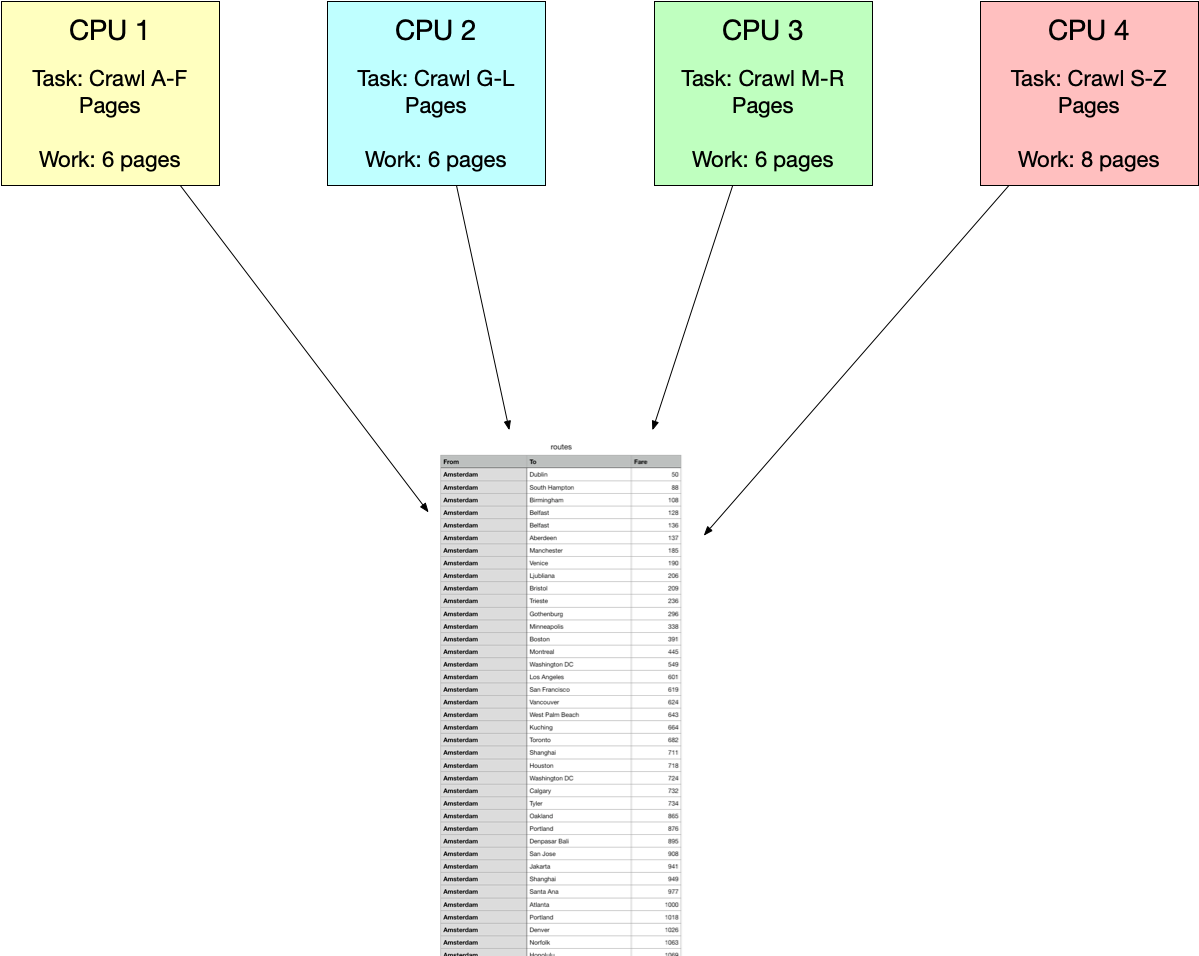
Here we knew that we were look at a static number of pages (i.e, 26 pages for all the letters in the alphabet). To assign each CPU (i.e., thread/goroutine running on that CPU) work, we equally distributed the number of pages to work based on dividing that static number of pages by the number of goroutines we were spawning:
threads = 4
workTotal = 26
workAmount = workTotal / threads // 26/4 == 6 (integer division)
However, if each worker is assigned 6 pages then there are 2 pages left that need to be processed. The easiest solution is to assign the last goroutine (i.e., goroutine 4) the remaining work. Thus, goroutine will process 8 pages instead of 6. This issue is one of the disadvantages of this method (along with other problems) because it can result in the last goroutine performing more work that could be handled by other goroutines to help with performance. We will discuss in a future modules about how to improve on this technique and look at better ones but for this homework assignment it’s fine to assign the last thread the remaining work.
I recommend you use the following goroutine function header for this assignment (and potentially future assignments):
type WorkerContext struct {
// Define your shared variables
}
func worker(ctx *WorkerContext, work **SOME TYPE**) {
}
All workers (i.e., goroutines) will be spawned from the main function to be assigned the worker
function. The ctx argument is the shared context that holds all the shared variables (e.g., sync.WaitGroup, atomic flags, etc.) to all the goroutines that need access to them. Specifically, for a static work distribution, the work argument will tell the worker what work they are assigned. This could also be done with more than just a single argument. For example, in the crawler program, worker 1 is assigned pages A-F and only should be performing the necessary computations on those distinct pages. At the end of its computation, it will communicate its results via a shared variable. You will need to think about how to accomplish this part.
Problem 1: Estimating Pi using the Infinite Series method¶
Inside the pi directory, open the file called pi.go and write a concurrent Go program that uses a infinite series method to estimate pi. The sequential implementation of this method is implement here
Jump to the An Infinite Series Approach section, use that approach as your basis for implementing the parallel version. Only look at the arc_tan_estimation code example.
The program must use the following usage and have the these required command-line arguments
const usage = "Usage: pi interval threads\n" +
" interval = the number of iterations to perform\n" +
" threads = the number of threads (i.e., goroutines to spawn)\n"
The main goroutine should read in the interval and threads argument and only print the estimate of pi. The program must use the fork-join pattern described in class and a static task distribution technique. The threshold for running the sequential version is 1000 intervals (even though the threads value is always set); otherwise, you must run the parallel implementation.
Assumptions: You can assume that interval and threads will always be given as integers and be provided. Thus, you do not need to perform error checking on those arguments. You also will not need to print out the usage statement for this problem. The usage is given here for clarification purposes.
Sample Runs ($: is just mimicking the command line)
$: go run hw2/pi 100 2
3.1315929036
$: go run hw2/pi 10 1
3.0418396189
$: go run hw2/pi 10 3
3.0418396189
The tests for this problem is inside pi_test.go. Please go back to homework #1 if you are having trouble running tests.
Problem 2: Waitgroup Implementation¶
Read the following about go interfaces before starting this problem:
Inside the waitgroup directory, open the file called waitgroup.go. Consider the following interface and function:
type WaitGroup interface {
Add(amount uint)
Done()
Wait()
}
// NewWaitGroup returns a instance of a waitgroup
// This instance must be a pointer and should not
// be copied after creation.
func NewWaitGroup() WaitGroup {
//IMPLEMENT ME!
}
Provide an implementation of a WaitGroup that mimics the Go implementation:
The only difference is that our implementation does not allow negative integers to be passed to the Add method. Remember, you can only use atomic operations in this implementation. Don’t overthink this problem. Many of these methods can be implemented in very few lines.
The tests for this problem is inside waitgroup_test.go. Please go back to homework #1 if you are having trouble running tests.
IMPORTANT: For this problem, you can only use the CompareAndSwapInt64 and StoreInt64 atomic operations for synchronization. No other atomics can be used in this implementation.
Problem 3: Wrangling COVID Data¶
One of the tedious tasks data scientists have to perform is data wrangling, which is the process of gathering, and transforming data to get ready for doing data analytics. The raw data may have empty fields, duplicated records, be dispersed among many files, etc. For this problem, we will take a look at zip code COVID data from the Chicago Data Portal:
Unfortunately, for you, data you will be processing is the same data provided by the link above but needs to be wrangled. Inside the covid/data directory, and look at the README.txt to see how you can download the data.
DO NOT INCLUDE THE DATA FILES TO YOUR REPO!!. The gitignore file thats included in your repositories should already handle this so please make sure to not modify or force the commit of the data files.
Here is additional information about the data:
The data is dispersed between multiple files with the format
covid_NUM.csv, whereNUMis an integer. There is a static number of files that is equal to500.Each file may contain a subset of the original file records. The original file that comes from the link above is named
covid_sample.csvand is included in the data directory. You can use this file to help with testing your code.The files also have duplicated records between them, which you will need to ignore when performing the main computation.
Each file begins with the original header.
Main task: Your task is to write a concurrent program inside covid/covid.go that calculates the total number of cases, tests, and deaths for a zip code in a given month and year. The output of the program must be a string that of the format: TOTAL_NUM_CASES,TOTAL_NUM_TESTS,TOTAL_NUM_DEATHS, where TOTAL_NUM_CASES, TOTAL_NUM_TESTS, and TOTAL_NUM_DEATHS are the cumulative counts for each category, which are all separated by a single comma. Nothing else should be printed to the console. For guidance, you should only be looking at the columns:
ZIP Code
Week Start
Cases - Weekly
Tests - Weekly
Deaths - Weekly
For verifying if a record is part of the month and year specified, the program just checks the month component of the "Week Start" column. If it matches the month and year given to the program then count that record as part of the total calculations. The format for the date will always be "MONTH/DAY/YEAR". We know some weeks overlap the beginning of other months but to keep this problem simple we will just look at the "Week Start" column. If a record for any of those specified columns do not contain a value (i.e., a column has missing data) OR does not match the zip code, month, year specified by the user then your program skips the entire record (i.e., that record is not included in the total counts). To help you know the indices for these columns, you can use the following code:
const zipcodeCol = 0
const weekStart = 2
const casesWeek = 4
const testsWeek = 8
const deathsWeek = 14
Your program must implement the following parallel patterns
Fork-join pattern with static work distribution by assigning the goroutines a static amount of files to work on in order to calculate these numbers. You don’t need to have a sequential threshold for this problem. You will always just run the parallel version.
Map pattern - this has the same structure of a fork-join pattern with the only difference being that it instead of a static task distribution scheme you will spawn one goroutine to process a single file. This means you will ignore
-threadsargument for this pattern.
The program must have the following usage statement:
const usage = "Usage: covid [-mode=value] [-threads=int] zipcode month year\n" +
" zipcode = a possible Chicago zipcode\n" +
" month = the month to display for that zipcode \n" +
" year = the year to display for that zipcode \n" +
" -threads = optional the number of threads (i.e., goroutines to spawn) set to number of logical cores by default\n" +
" -mode value = optional values: static= static dist (fork-join), map = map dist \n"
Sample Runs ($: is just mimicking the command line)
$: go run covid.go -mode=static 60603 5 2020
2,48,0
$: go run covid.go -mode=map -threads=4 60640 2 2021
182,9961,5
$; go run covid.go -mode=static -threads=3 89149 2 2020
0,0,0
Additionally you program must also implement a sequential version of this program that processes each file one by one. If the user does not enter in the -mode flag then it runs the sequential version by default.
If the user does not set the -threads flag then for a fork-join pattern with static work distribution will be set to runtime.NumCPU() (i.e., the number of logical cores on the machine).
Assumptions: You can assume that zipcode, month and year will always be provided. -threads, month and year are always given as integers. month will always be a value between [1-12], threads wil always be greater than zero and year will always be [2020-2021]. The value for the flag -mode=value will always be either static for running the fork-join with static distribution pattern or map for running the map parallel pattern. Thus, you do not need to perform error checking on those arguments. However, the program could be given an invalid zipcode, which should result in the string "0,0,0".
- Helpful Hints:
Use
fmt.Sprintfto create a formatted string andstrings.Jointo join together a slice of strings into a single string.Use CSV package csv
State that empty column values are empty strings
Go Maps (e.g.,
map[TYPE]type) will be helpful here.
The tests for this problem is inside covid_test.go. Please go back to homework #1 if you are having trouble running tests.
Program Performance¶
Do not worry about the performance of your programs for this week. We will reexamine these implementations for the next homework assignment once you a better understanding about parallel performance, which is covered in module 3.
Grading¶
Programming assignments will be graded according to a general rubric. Specifically, we will assign points for completeness, correctness, design, and style. (For more details on the categories, see our Assignment Rubric page.)
The exact weights for each category will vary from one assignment to another. For this assignment, the weights will be:
Note
Your code must be deterministic. This note means that if your code is running and passing the tests on your local machine or on CS remote machine but not on Gradescope this means you have a race condition that must be fixed in order for you to get full completeness points.
Completeness: 65%
Correctness: 10%
Design & Style 5%
Short Answer Questions 20%
Obtaining your test score¶
The completeness part of your score will be determined using automated
tests. To get your score for the automated tests, simply run the
following from the Terminal. (Remember to leave out the
$ prompt when you type the command.)
$ cd grader
$ go run hw2/grader hw2
This should print total score after running all test cases inside the individual problems. This printout will not show the tests you failed. You must run the problem’s individual test file to see the failures.
Design, Style and Cleaning up¶
Before you submit your final solution, you should, remove
any
Printfstatements that you added for debugging purposes andall in-line comments of the form: “YOUR CODE HERE” and “TODO …”
Think about your function decomposition. No code duplication. This homework assignment is relatively small so this shouldn’t be a major problem but could be in certain problems.
Go does not have a strict style guide. However, use your best judgment from prior programming experience about style. Did you use good variable names? Do you have any lines that are too long, etc.
As you clean up, you should periodically save your file and run your code through the tests to make sure that you have not broken it in the process.
Submission¶
Before submitting, make sure you’ve added, committed, and pushed all your code to GitHub. You must submit your final work through Gradescope (linked from our Canvas site) in the “Homework #2” assignment page via two ways,
Uploading from Github directly (recommended way): You can link your Github account to your Gradescope account and upload the correct repository based on the homework assignment. When you submit your homework, a pop window will appear. Click on “Github” and then “Connect to Github” to connect your Github account to Gradescope. Once you connect (you will only need to do this once), then you can select the repository you wish to upload and the branch (which should always be “main” or “master”) for this course.
Uploading via a Zip file: You can also upload a zip file of the homework directory. Please make sure you upload the entire directory and keep the initial structure the same as the starter code; otherwise, you run the risk of not passing the automated tests.
Note
For either option, you must upload the entire directory structure; otherwise, your automated test grade will not run correctly and you will be penalized if we have to manually run the tests. Going with the first option will do this automatically for you. You can always add additional directories and files (and even files/directories inside the stater directories) but the default directory/file structure must not change.
Depending on the assignment, once you submit your work, an “autograder” will run. This autograder should produce the same test results as when you run the code yourself; if it doesn’t, please let us know so we can look into it. A few other notes:
You are allowed to make as many submissions as you want before the deadline.
Please make sure you have read and understood our Late Submission Policy.
Your completeness score is determined solely based on the automated tests, but we may adjust your score if you attempt to pass tests by rote (e.g., by writing code that hard-codes the expected output for each possible test input).
Gradescope will report the test score it obtains when running your code. If there is a discrepancy between the score you get when running our grader script, and the score reported by Gradescope, please let us know so we can take a look at it.