Class Meeting 09: Reinforcement Learning
Today's Class Meeting
- Learning about reinforcement learning (here's a link to the slides)
- Gaining intuition about reinforcement learning, and specifically the Q-learning algorithm, through a class exercise
What You'll Need for Today's Class
- Some scratch paper work through some of today's class exercises
Q-Learning Algorithm
\(\textrm{Algorithm Q_Learning}:\)
\( \qquad \textrm{initialize} \: Q \)
\( \qquad t = 0 \)
\( \qquad \textrm{while} \: Q \: \textrm{has not converged:} \)
\( \qquad \qquad \textrm{select} \: a_t \: \textrm{at random} \)
\( \qquad \qquad \textrm{perform} \: a_t \)
\( \qquad \qquad \textrm{receive} \: r_t \)
\( \qquad \qquad Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \cdot \Big( r_t + \gamma \cdot \: \textrm{max}_a
Q(s_{t+1}, a) - Q(s_t, a_t) \Big)\)
\( \qquad \qquad t = t + 1\)
Where:
- \(Q: S \times A \rightarrow \mathbb{R} \), meaning that for a given state \( (s_t) \) and action \( (a_t) \), \(Q(s_t, a_t)\) is a real number \((\mathbb{R})\)
- \(s_t \in S\) represents the state space - all possible states of the world
- \(a_t \in A\) represents the action space - all possible actions the robot could take
- \(r_t \) is the reward received when action \(a_t\) is taken from state \(s_t\) according to the reward function \(r(s_t, a_t)\)
- \(\alpha\) represents the learning rate \((0 \lt \alpha \le 1) \), the closer to 1 the learning rate is, the more rapidly your Q-matrix will update to observed rewards; for today's class we'll work with values of \( \alpha = 1\)
- \(\gamma\) is the discount factor where \((0 \le \gamma \lt 1) \), which indicates how much future rewards are considered in the actions of a system, \(\gamma = 0\) would indicate a scenario in which a robot only cares about the rewards it could get in a single moment, as where \(\gamma = 1\) indicates a scenario where the robot doesn't care at all about the short term and pursues whatever actions will produce the best long-term reward (regardless of how long that takes), for this project, we recommend choosing a value for \(\gamma\) somewhere in between 0 and 1
Class Exercise: Q-Learning in a 5 Room Building
For today's class exercise, please get together in groups of 2-3 students.
Specifying the MDP Model
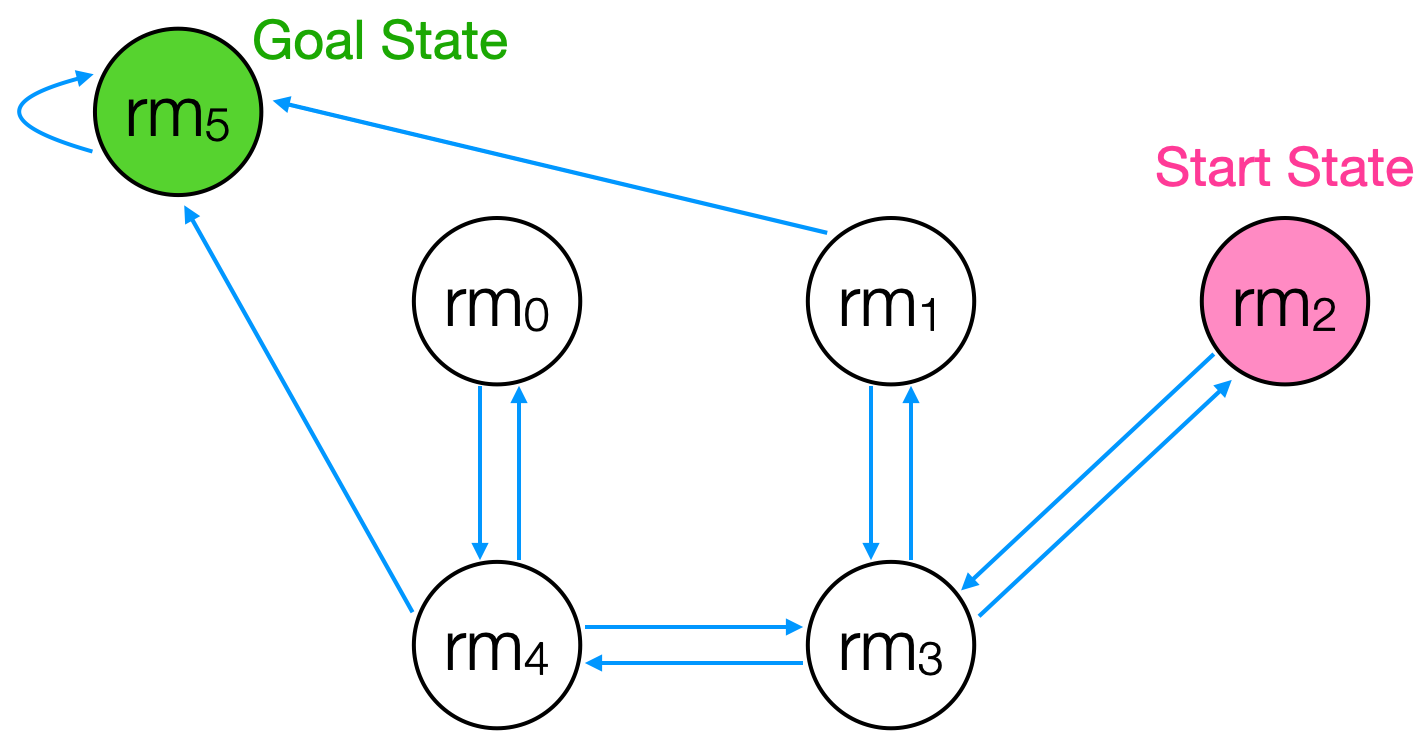
Let's consider a situation in which our Turtlebot3 robot is placed inside a building that has a floorplan like that shown in the following image.
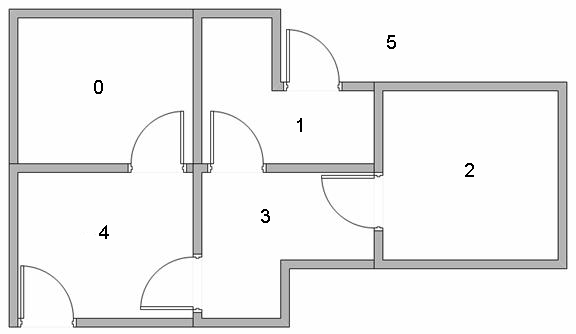
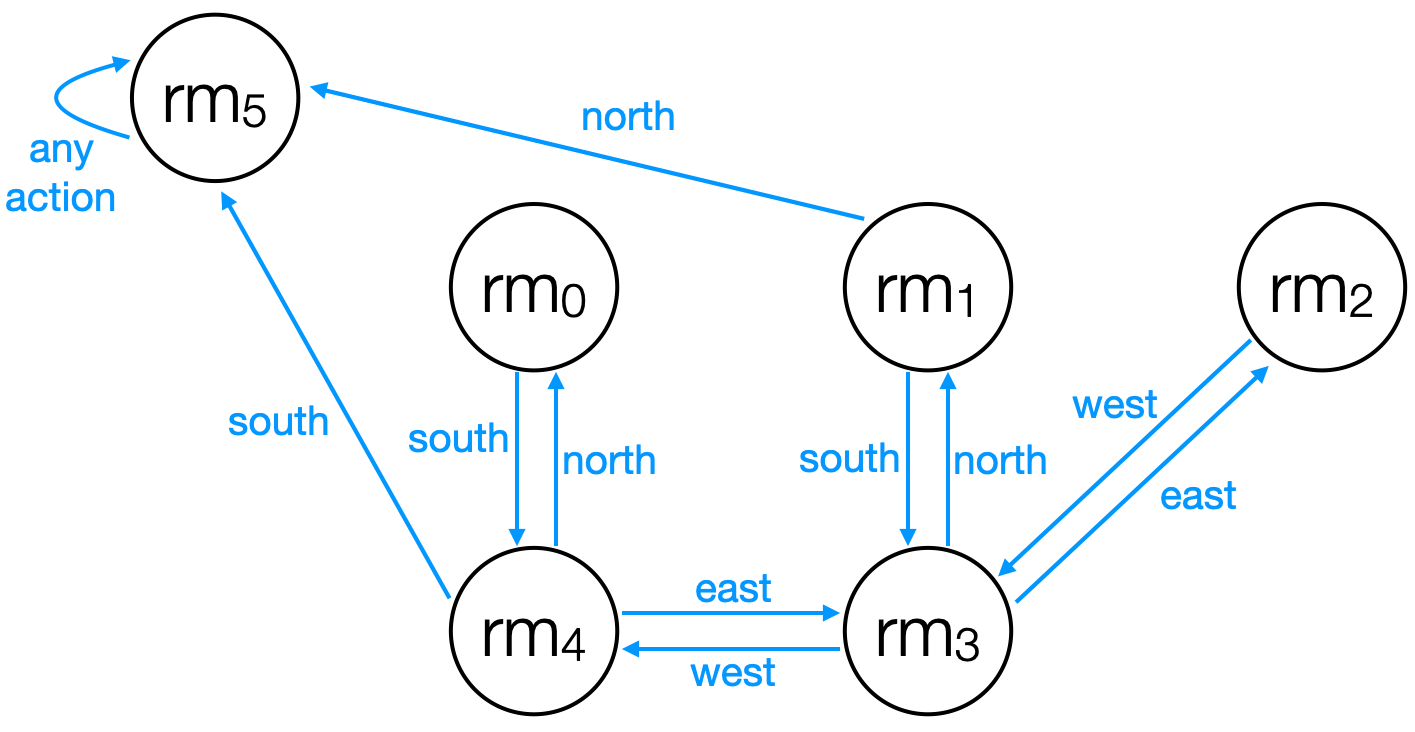
We can characterize this space as an MDP, where each state represents one room in the building (or outside, e.g., room 5) and where the agent can transition between rooms by moving either north, south, east, or west. The agent cannot stay in the same state from time step to time step, except once it is outside.
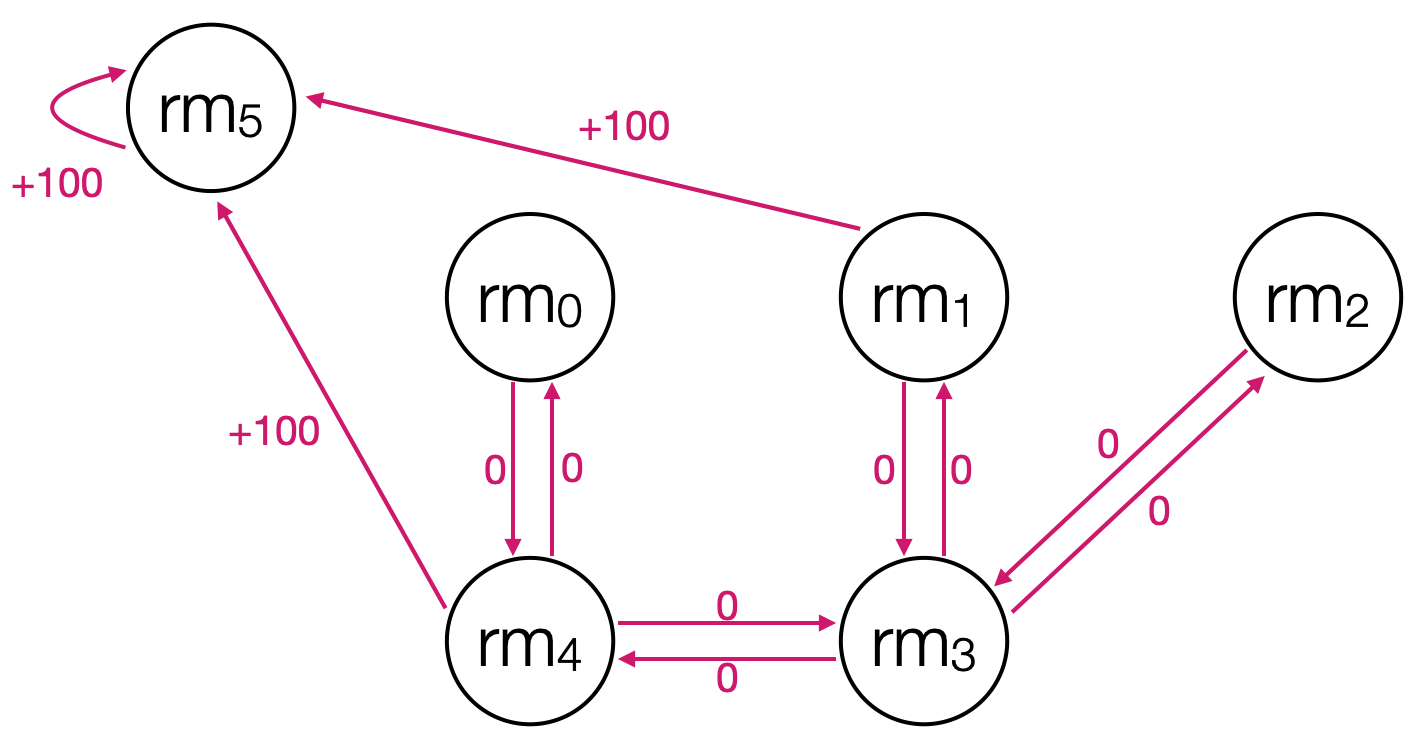
We can specify the reward function as depicted in the following diagram, where the agent receives a reward when it transitions outside from either room 1 or room 4. Additionally, the agent continues reaping rewards once it's already outside every time step.
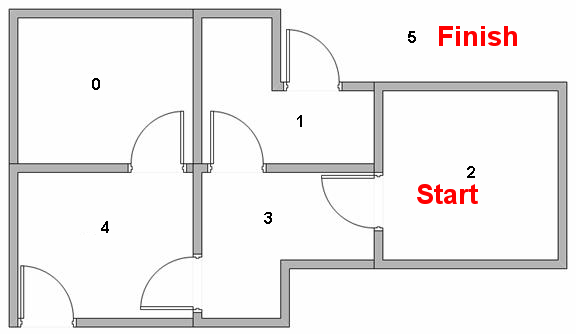
Our robot's goal in this world is to get outside (room 5) from it's starting position in room 2.
Applying the Q-Learning Algorithm in this World
The following table / matrix can be used to represent \(Q(s_t, a_t)\), where the rows represent the world states (rooms) and the columns represent actions that the robot can take. The following table is initialized where all valid state-action pairs are initialized to 0 and and invalid state-action pairs are initialized to -1.
| North | South | East | West | |
|---|---|---|---|---|
rm0
| -1 |
0 |
-1 |
-1 |
|
rm1
| 0 |
0 |
-1 |
-1 |
|
rm2
| -1 |
-1 |
-1 |
0 |
|
rm3
| 0 |
-1 |
0 |
0 |
|
rm4
| 0 |
0 |
0 |
-1 |
|
rm5
| 0 |
0 |
0 |
0 |
|
Your goal in this exercise is to update \(Q(s_t, a_t)\) according to the Q-learning algorithm. In this exercise we will make the following assumptions:
- \(\alpha = 1\), so the Q-learning update rule is thus: \(Q(s_t, a_t) \leftarrow r_t + \gamma \cdot \: \textrm{max}_a Q(s_{t+1}, a) \)
- \(\gamma = 0.8\), the discount factor
- Transitions are always made successfully (it's not possible for our agent to fail in its attempt to take an action)
Here are action trajectories that you'll have your robot agent follow through the environment (assume that your agent always starts in room 2 at the beginning of each trajectory). For each action within each trajectory, update \(Q(s_t, a_t)\) according to the Q-learning algorithm. You can check your answers on this page, which provides \(Q(s_t, a_t)\) after each trajectory.
- Trajectory 0: west, west, south, north
- Trajectory 1: west, north, north, south
- Trajectory 2: west, west, north, south, south
- Trajectory 3: west, west, east, north, north
More on Reinforcement Learning
If you wan to learn more about reinforcement learning or go further into the topic introduced in class, please check out:
- Kaelbling, L. P., Littman, M. L., & Moore, A. W. (1996). Reinforcement learning: A survey. Journal of artificial intelligence research, 4, 237-285.
- The Reinforcement Learning Udacity course taught by Charles Isbell and Michael Littman
Acknowledgments
The lecture for today's class was informed by Kaelbling et al. (1996), Charles Isbell and Michael Littman's Udacity course on Reinforcement Learning, and geeksforgeeks.org's article on the upper confidence bound for reinforcement learning. The class exercise for today was inspired by the Q-learning tutorial on mnemstudio.org.