Mining Current Population Survey (CPS) Data¶
Due: Friday, November 17 at 4pm
The goal of this assignment is to give you experience using the pandas data analysis library. In general, it will also give you experience using a well-documented third-party library, and navigating their documentation in search of specific features that can help you complete your implementation.
Current Population Survey (CPS)¶
The Current Population Survey (CPS) is the U.S. Government’s monthly survey of unemployment and labor force participation. The survey data, compiled by the National Bureau of Economic Research (NBER), are freely available to the public and come in several forms. The Merged Outgoing Rotation Groups (MORG) datasets are the easiest to use, because NBER has already done high-quality “pre-processing” work on the raw survey data to make sure that everything is logical and consistent. You can refer to the CPS website for more details.
In this programming assignment, you will use pandas to examine and
make interesting observations from the MORG datasets in years 2007,
2010, and 2014. More data are available on the CPS website. Feel free
to explore CPS on your own after the assignment. You should have all
the necessary programming skills to do so!
Getting started¶
See these start-up instructions if you intend to work alone.
See these start-up instructions if you intend to work with the same partner as in a previous assignment.
See these start-up instructions if you intend to work in a NEW pair.
The pa6 directory includes a file named cps.py, which you
will modify, a file named pa6_helpers.py that contains a few useful
functions, and a file named test_cps.py with tests.
Please put all of your code for this assignment in cps.py.
Do not add extra files.
The data/ directory contains a file called get_files.sh that will download
the data files necessary for this assignment, along with some files needed by the tests.
To download all the files, go into the data directory and run this command:
./get_files.sh
Please note that you must be connected to the network to use this script.
- Do not add the data files to your repository! If you wish to use both
- CSIL & the Linux servers and your VM, you will need to run the
get_files.shscript twice once for CSIL & the Linux servers and once for your VM.
We suggest that, as you work through the assignment, you keep an IPython session open to test the functions you will implement in cps.py:
In [1]: %load_ext autoreload
In [2]: %autoreload 2
In [3]: import pandas as pd
In [4]: import cps
Data¶
Ten data files are used for this programming assignment:
morg_d07.csv,morg_d10.csv, andmorg_d14.csv: MORG datasets for 2007, 2010, and 2014.morg_d07_mini.csv,morg_d10_mini.csv, andmorg_d14_mini.csv: Abridged versions of the MORG datasetsgender_code.csv,race_code.csv,ethnic_code.csv, andemployment_status_code.csv: These files contain information about several codes that appear in the MORG datasets.
All of these files are in comma-separated value (CSV) format. Each
file can be understood to represent a table with multiple rows and
columns (in fact, the CSV format is supported by most spreadsheet
programs, and you can try opening these files in Excel, Libreoffice
Calc, etc.). The first line of the file is the header of the
file. It contains the names of the columns, separated by commas. After
the header, each line in the file represents a row in the table,
with each value in the row (corresponding to the columns specified in
the header) separated by a comma. A common way to refer to a value in
a row is as a field. So, if a CSV file has an age column, in an
individual row we would refer to the age field (instead of column,
which tends to refer to an entire column of values).
MORG Files¶
The files morg_d07.csv, morg_d10.csv, and morg_d14.csv
contain data extracted from
the 2007, 2010, and 2014 MORG datasets, respectively. In all of these
files, each row corresponds to the survey data obtained from a unique
individual. We consider the following variables for each individual in
this assignment (although there are a lot more variables available in
the MORG datasets):
h_id: a string that serves as a unique identifier, which we created by concatenating several variables in the original MORG datasets.age: an integer value specifying the age of the individual.gender_code: an integer value that encodes the gender (or sex) of the individual.race_code: an integer value ranging from 1 to 26 that represents different races.ethnicity_code: which, if present, is an integer value ranging from 1 to 8, representing a Hispanic ethnicity. If the value is missing, the individual should be considered “Non-Hispanic” (code: 0).employment_status_code: an integer value between 1 and 7 that specifies employment status.hours_worked_per_week: an integer that specifies the usual weekly work hours of an individual.earnings_per_week: a float that indicates the weekly earnings of an individual.
The CSV file has a column for each of these variables. Here are the first few lines from morg_d14.csv, including the header:
h_id,age,gender_code,race_code,ethnicity_code,employment_status_code,hours_worked_per_week,earnings_per_week
1_1_1,32,2,2,,1,40,1250
1_2_2,80,2,1,,7,,
1_3_3,20,2,2,,7,,
1_4_4,28,1,1,,1,40,1100
1_5_5,32,1,1,,1,52,1289.23
1_6_6,69,2,1,,5,,
1_7_7,80,2,1,,5,,
1_8_8,31,1,1,,1,45,866.25
1_9_9,68,2,1,,1,10,105
The files morg_d07_mini.csv, morg_d10_mini.csv, and
morg_d14_mini.csv contain “mini” versions of the full MORG
datasets. They have the same columns as the MORG datasets, but only
contain 20 sample rows from the original files. These “mini” files
are small enough so that you can work out answers to each task in the
assignments by hand. We have supplied a few basic tests, which use
these files, for each task. Once your code passes our tests, you
should come up with your own tests for the full data sets and for any
special cases that are not covered by our tests.
Code files¶
Many of the values stored in the MORG files are coded; that is, an
integer value is used in place of a more descriptive string. This type of coding is
often used to save space. All of the code files—
employment_status_code.csv, ethnic_code.csv,
gender_code.csv, race_code.csv —have the same format: a
two-column header followed by a series of rows each of which has an integer code
and the corresponding string.
For example, the file employment_status_code.csv has two columns:
employment_status_code, same as theemployment_status_codecolumn in the MORG datasets.employment_status_string, a string that describes the employment status.
Here are the first few lines from this file:
employment_status_code,employment_status_string
1,Working
2,With a job but not at work
3,Layoff
4,Looking
Take a look at these files to familiarize yourself with the structures. Remember that, in all of these files, the first line is a header with the names of the columns, and every subsequent line represents a row with fields corresponding to the columns specified in the header.
At the beginning of cps.py, we have provided a dictionary CODE_TO_FILENAME that maps the name
of a coded column in the MORG dataset, such as "gender_code", to the name of the
corresponding code file.
Pandas¶
You could easily write the code for this assignment using the csv
library, lists, dictionaries, and loops. In fact, a few years ago, we did a
similar assignment using exactly those constructs. The purpose of
this assignment, however, is to help you become more comfortable using
pandas. As a result, you are required to use pandas data
frames to store the data and pandas methods to do the necessary
computations.
Some of the tasks we will ask you to do require using features in
pandas that have not been covered in class.
This is by design: one of the goals of this assignment is for you to be
able to read and use external documentation. So, when figuring out
these tasks, you are allowed (and, in fact, encouraged) to look at the
Pandas documentation.
Not just that, any
code you find on the Pandas documentation can be incorporated into
your code without attribution. However, if you find Pandas examples
elsewhere on the Internet, and use that code either
directly or as inspiration, you must include a code comment specifying
its origin.
When solving the tasks in this assignment, you should assume that any computation on the data can be done by calling a series of Pandas operations. Before trying to implement anything, you should spend some time trying to find the right methods for the task. We also encourage you to experiment with them on IPython before you incorporate them into your code.
Our implementation used filtering and vector operations, as
well as methods like concat, cut, fillna, Categorical.from_codes,
isin, max, mean, median, min, read_csv,
rename, sort_index, and value_counts along with a small
number of lists and loops. Do not worry if you are not using all
of these methods!
Your tasks¶
Task 1: Building a dataframe from the CSV files¶
Your first task is to complete the function build_morg_df in
cps.py. This function takes the name of a MORG file as an
argument and should return a pandas dataframe, if the file exists.
If the file does not exist, you should return None. (You can use
the library function os.path.exists to determine whether a file
exists.)
We will refer to a dataframe produced by this function as a MORG dataframe.
MORG dataframes must have columns for:
h_id: stringage: integergender: categoricalrace: categoricalethnicity: categoricalemployment_status: categoricalhours_worked_per_week: floatearnings_per_week: float
in that order. We defined constants for the column names: HID,
AGE, etc.
pandas provides a read_csv function that you can use to
read the file into a dataframe. The read_csv function will
convert the values for h_id, age, hours_worked_per_week
and earnings_per_week into the
correct types automatically. If you look at the data carefully, you
will notice that the values corresponding to hours worked per week and
earnings per week are missing in some of the samples. These values
will appear as NaN, which stands for “not a number” in the
dataframe.
The read_csv function will not handle the conversion from coded values
to categorical values and
so, you must write code to convert the coded values for gender, race,
ethnicity, and employment status to categorical values and to rename
the columns.
Take into account that categorical data is a type of column that we
covered briefly in class. You should read up on it to make
sure you use it correctly. Please note that you must use
a categorical column for gender, race, and ethnicity. You
cannot just use merge to merge in the string values of the codes.
We suggest that you start by trying code in your IPython session. A good
starting point is to load one of the “mini” datasets using read_csv:
In [5]: df = pd.read_csv("data/morg_d07_mini.csv")
If we print out the columns and the dataframe itself, you’ll see how it contains the same data as in the CSV file, including the codes for gender, race, and ethnicity:
In [6]: df.columns
Out[6]:
Index(['h_id', 'age', 'gender_code', 'race_code', 'ethnicity_code',
'employment_status_code', 'hours_worked_per_week', 'earnings_per_week'],
dtype='object')
In [7]: df
Out[7]:
h_id age gender_code race_code ethnicity_code \
0 1_1_1 32 2 2 NaN
1 1_34_34 60 2 1 NaN
2 1_46_46 28 1 1 4.0
3 1_554_554 29 1 1 NaN
4 1_666_666 46 2 1 NaN
5 2_1314_1314 17 1 1 NaN
6 6_6898_6898 67 1 1 4.0
7 6_7346_7346 54 2 2 NaN
8 8_9768_9768 36 1 1 NaN
9 9_11763_11763 49 1 1 NaN
10 18_23481_23481 47 2 1 NaN
11 19_24212_24212 38 1 4 NaN
12 20_25196_25196 42 1 7 1.0
13 20_25289_25289 55 2 14 NaN
14 20_25582_25582 21 1 3 5.0
15 20_25624_25624 37 2 4 NaN
16 21_26276_26276 60 1 4 NaN
17 13_137361_18675 38 1 1 1.0
18 24_178642_30613 20 2 2 NaN
19 2_1088_1088 56 1 2 NaN
employment_status_code hours_worked_per_week earnings_per_week
0 1 40.0 1250.00
1 1 40.0 538.46
2 1 40.0 380.00
3 1 40.0 890.00
4 1 10.0 0.00
5 1 35.0 290.50
6 1 40.0 500.00
7 1 40.0 2173.07
8 1 50.0 2884.00
9 1 50.0 500.00
10 1 40.0 512.00
11 1 38.0 550.00
12 1 40.0 484.40
13 1 39.0 327.60
14 1 25.0 146.25
15 1 40.0 711.53
16 1 50.0 1442.30
17 3 NaN NaN
18 3 NaN NaN
19 4 NaN NaN
Experiment with this dataframe and see if you can convert the coded values into categorical values. If you mess up your dataframe, just re-run this to return to square one:
df = pd.read_csv("data/morg_d07_mini.csv")
Once you’ve figured out how to convert the coded values into categorial
values, put the code into the cps.py file. You can then check
whether build_morg_df is returning the expected dataframe. For
example:
In [8]: d07 = cps.build_morg_df("data/morg_d07_mini.csv")
In [9]: d07.columns
Out[9]:
Index(['h_id', 'age', 'gender', 'race', 'ethnicity', 'employment_status',
'hours_worked_per_week', 'earnings_per_week'],
dtype='object')
In [10]: d07
Out[10]:
h_id age gender race \
0 1_1_1 32 Female BlackOnly
1 1_34_34 60 Female WhiteOnly
2 1_46_46 28 Male WhiteOnly
3 1_554_554 29 Male WhiteOnly
4 1_666_666 46 Female WhiteOnly
5 2_1314_1314 17 Male WhiteOnly
6 6_6898_6898 67 Male WhiteOnly
7 6_7346_7346 54 Female BlackOnly
8 8_9768_9768 36 Male WhiteOnly
9 9_11763_11763 49 Male WhiteOnly
10 18_23481_23481 47 Female WhiteOnly
11 19_24212_24212 38 Male AsianOnly
12 20_25196_25196 42 Male White-AI
13 20_25289_25289 55 Female AI-HP
14 20_25582_25582 21 Male AmericanIndian/AlaskanNativeOnly
15 20_25624_25624 37 Female AsianOnly
16 21_26276_26276 60 Male AsianOnly
17 13_137361_18675 38 Male WhiteOnly
18 24_178642_30613 20 Female BlackOnly
19 2_1088_1088 56 Male BlackOnly
ethnicity employment_status hours_worked_per_week earnings_per_week
0 Non-Hispanic Working 40.0 1250.00
1 Non-Hispanic Working 40.0 538.46
2 Dominican Working 40.0 380.00
3 Non-Hispanic Working 40.0 890.00
4 Non-Hispanic Working 10.0 0.00
5 Non-Hispanic Working 35.0 290.50
6 Dominican Working 40.0 500.00
7 Non-Hispanic Working 40.0 2173.07
8 Non-Hispanic Working 50.0 2884.00
9 Non-Hispanic Working 50.0 500.00
10 Non-Hispanic Working 40.0 512.00
11 Non-Hispanic Working 38.0 550.00
12 Mexican Working 40.0 484.40
13 Non-Hispanic Working 39.0 327.60
14 Salvadoran Working 25.0 146.25
15 Non-Hispanic Working 40.0 711.53
16 Non-Hispanic Working 50.0 1442.30
17 Mexican Layoff NaN NaN
18 Non-Hispanic Layoff NaN NaN
19 Non-Hispanic Looking NaN NaN
Notice how gender_code is now gender, and it contains a categorical value,
not a numerical code. That said, remember that you can’t just replace the codes
with their string representation! You have to create a categorical value; one way
of checking this is to look at the dtype attribute of a column. For example:
In [11]: d07["gender"].dtype
Out[11]: category
This means the column contains categorical values. If, on the other hand, dtype
is dtype('O'), then that means you’re not converting the coded values to
categorical values correctly.
Once you feel your build_morg_df function is in good shape, we have
provided a few basic tests. You can run them using the Linux command:
py.test -x -k build test_cps.py
Recall that the -x flag indicates that py.test should stop
as soon as one test fails. The -k flag allows you to reduce the set of
tests that is run. For example, using -k build will only run the
tests that include build in their names.
Remember that running the automated tests should come towards the end of your development process! Debugging your code based on the output of the tests will be challenging, so make sure you’ve done plenty of manual testing on IPython first.
Task 2: Weekly earnings statistics¶
For this task, we will consider full-time workers only.
A person is considered to be a full-time worker if and only if the employment status is Working and he or she works 35 or more hours each week.
Your task
is to implement the function
calculate_weekly_earnings_stats_for_fulltime_workers, which
calculates weekly earnings statistics (mean, median, min, max)
according to some query criteria specified in the function
arguments. In this task, gender, race, and ethnicity are used as query
criteria. There are four arguments to this function:
morg_df: a MORG dataframegender: which can be one of three valid string values,"Male","Female", and"All"race, which can be one of seven valid string values:"WhiteOnly""BlackOnly""AmericanIndian/AlaskanNativeOnly""AsianOnly"- “
Hawaiian/PacificIslanderOnly" "Other"(races not specified above)"All"(all races)
ethnicity, which can be one of three valid string values,"Hispanic","Non-Hispanic", and"All"(both Hispanic and Non-Hispanic individuals).
The return value of this function is a tuple that contains exactly four floats, reporting the mean, median, min, and max earning values (in that order) of the workers who fit the criteria.
If any argument is not valid, the function should return a tuple with 4 zeroes
(i.e., (0,0,0,0)). Moreover, if the given morg_df does not contain any
samples that meet the query criteria, the function should also return
(0,0,0,0).
Below are some examples uses of this function:
Calculate weekly earnings statistics for all female full-time workers in 2014:
In [5]: cps.calculate_weekly_earnings_stats_for_fulltime_workers(d14, "Female", "All", "All") Out[5]: (891.87419746754858, 738.0, 0.0, 2884.6100000000001)
Calculate weekly earnings statistics for White and Non-Hispanic full-time workers, both male and female, in 2007:
In [6]: cps.calculate_weekly_earnings_stats_for_fulltime_workers(d07, "All", "WhiteOnly", "Non-Hispanic") Out[6]: (921.56106244922512, 769.0, 0.0, 2884.6100000000001)
Calculate weekly earning statistics for all Hispanic full-time male workers in 2014:
In [7]: cps.calculate_weekly_earnings_stats_for_fulltime_workers(d14, "Male", "All", "Hispanic") Out[7]: (785.4366183924692, 607.5, 0.0, 2884.6100000000001)
As in the previous task, you should start by experimenting in your IPython session. Start by loading the full datasets like this:
In [5]: d07 = cps.build_morg_df("data/morg_d07.csv")
In [6]: d10 = cps.build_morg_df("data/morg_d10.csv")
In [7]: d14 = cps.build_morg_df("data/morg_d14.csv")
And try to write the code to answer the three queries shown above. Don’t worry about
how you would implement them inside the calculate_weekly_earnings_stats_for_fulltime_workers
function. Just see what Pandas methods will allow you to filter the data and compute
the values shown above. This will help you get comfortable with the necessary Pandas
methods before you start writing code in calculate_weekly_earnings_stats_for_fulltime_workers.
And, if you mess up your dataframes, just re-run the above three lines to reload the
dataframes.
Once you have a calculate_weekly_earnings_stats_for_fulltime_workers function you
are comfortable with (make sure you’ve also tested it from IPython!), you can run our
some basic tests using the Linux command:
py.test -x -k weekly test_cps.py
You will want to write some tests of your own to supplement ours.
You can use this function to compare the weekly earnings among 2007, 2010, and 2014 for different query criteria using the full MORG datasets, for example:
- “BlackOnly” by gender
- “WhiteOnly” by gender
- “Hispanic” by gender
Try these query criteria yourself. What do the statistics reveal? (you don’t need to include your answer to this in your assignment; we’re encouraging you to play with the data and see what it reveals)
Task 3: Generating histograms¶
Similar to task 2, we consider full-time workers only in this task (refer to task 2 for the definition of full-time workers).
For this task, you will implement the create_histogram function, which takes in the following arguments:
morg_df: a MORG dataframevar_of_interest: a string that describes what variable the histogram is created for. Any variable whose values are integers or floats can be used asvar_of_interest(e.g.,AGE,EARNWKE, etc.).num_buckets: an integer that specifies the number of buckets for the histogram.min_val: an integer or a float that specifies the minimal value (lower bound) for the histogram.max_val: an integer or a float that specifies is the maximal value (upper bound) for the histogram.
This function returns a list with num_buckets elements. The \(i^{\text{th}}\) element in the list holds the total number of samples whose var_of_interest values lie within the range
For example, if num_buckets is 6, min_val is 10.1, and max_val is 95.0, the histogram will have 6 buckets covering the following ranges:
[10.1, 24.25)
[24.25, 38.4)
[38.4, 52.55)
[52.55, 66.7)
[66.7, 80.85)
[80.85, 95.0)
You will find the function linspace
from the numpy library very useful for calculating the bucket
boundaries.
For example:
In [5]: d14_mini = cps.build_morg_df("data/morg_d14_mini.csv")
In [6]: cps.create_histogram(d14_mini, cps.AGE, 10, 20, 50)
Out[6]: [2, 0, 1, 0, 1, 0, 1, 1, 1, 1]
In this example, the histogram has 10 buckets. The first element is two, because there are two individuals whose employment status is “Working” and whose age is between 20 (inclusive) and 23 (exclusive) in the 2014 mini MORG dataset (one with age 21, the other with age 22). The second element is zero because there are no individuals whose age is between 23 (inclusive) and 26 (exclusive).
Similarly, we can use the same function to create histograms for hours worked per week and earnings per week.
This is more interesting if we can visualize the histograms. We
provide a function plot_histogram in pa6_helpers.py to do
this. Plot two histograms using the following code with the full MORG
dataset from 2014:
In [5]: import pa6_helpers
In [6]: d14 = cps.build_morg_df("data/morg_d14.csv")
In [7]: hours_histogram_2014 = cps.create_histogram(d14, cps.HRWKE, 20, 35, 70)
In [8]: pa6_helpers.plot_histogram(hours_histogram_2014, 35, 70, "task2hours.png")
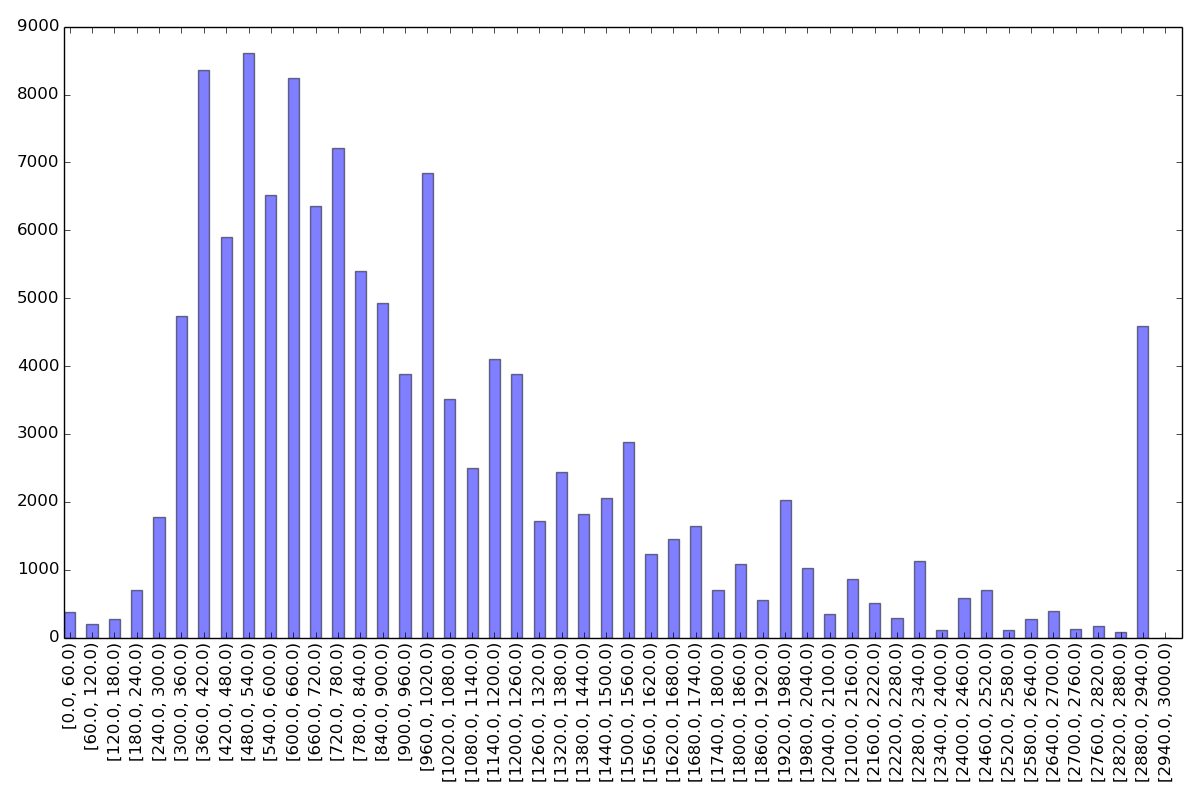
In [9]: earnings_histogram_2014 = cps.create_histogram(d14, cps.EARNWKE, 50, 0, 3000)
In [10]: pa6_helpers.plot_histogram(earnings_histogram_2014, 0, 3000, "task2earnings.png")
Take a look at the output PNG files (task2earnings.png and
task2hours.png) using the Linux command eog. What do these
histograms tell you?
We included the expected histogram plots below for your reference. These histograms make substantive sense:
- The earnings histogram does not follow the normal distribution. Instead, it is “right skewed”, meaning that there are more people with low earnings than those with high earnings.
- There is an abrupt change at the end of the earnings histogram. This is because, the values of weekly earnings are “top coded” due to confidentiality reasons. In this specific case, what happened is that anyone who earned more than 2884.61 dollars was reported as earning 2884.61 dollars exactly. If the accurate amounts were recorded, we expect that the histogram will have a much longer and smoother tail. Although less obvious, the data might have been “bottom coded” as well, i.e., weekly earnings below a certain value were reported as 0 (or 1).
- In the hours histogram, notice that there are a lot of people who worked between 38.5 to 40.25 hours. This may be an artifact: most people do not keep track of exactly how many hours they work every week, and they tend to report 40 as the “standard” answer.

You can generate similar histograms for years 2007 and 2010, and compare the histograms among the three years. Do not submit the PNG files.
You can run our basic tests on your function by running the Linux command:
py.test -x -k histogram test_cps.py
You will want to write some tests of your own to supplement ours.
Task 4: Unemployment rates¶
A person is considered to be in the labor force if his or her employment is "Working",
"Layoff" or "Looking", and considered to be unemployed if his or her employment
status is "Layoff" or "Looking". The unemployment rate is the percentage of people
in the labor force who are unemployed.
In this task, you will implement a function for calculating unemployment rates grouped based on a variable of interest for workers that fall in a specified age range. The calculate_unemployment_rates function takes in three arguments:
filename_list: a list of tuples, where each tuple contains a year (a two-digit string) and the file with the CPS MORG data for thatc year. For example,(10, "data/morg_d10.csv"))age_range: a two-integer tuple that specifies (age lower bound, age upper bound), both inclusive.var_of_interest: a string that describes which variable should be used to further breakdown the unemployment rates. The valid values forvar_of_interestareGENDER,RACE, andETHNIC.
The function calculate_unemployment_rates should return a
dataframe where the columns correspond to years and the rows
correspond to possible values for the variable of interest.
For example:
In [5]: unemp = cps.calculate_unemployment_rates([("14", "data/morg_d14.csv"), ("10", "data/morg_d10.csv"), ("07", "data/morg_d07.csv")],
...: (50, 70),
...: cps.GENDER)
...:
In [6]: unemp
Out[6]:
07 10 14
gender
Female 0.035537 0.073800 0.048915
Male 0.042502 0.102031 0.056111
Notice how the columns (the years) are not in the order in
which the years were provided in the filename_list parameter.
Instead, they must be sorted in increasing order. Similarly,
the rows must also be sorted in increasing order (in this case,
by the gender string).
While it is nice to be able to take a quick look at the data in the IPython session, the resulting output is not very pretty. Fortunately, there is a Python library named tabulate that takes data in several forms, including dataframes, and generates nice looking tables. This library is easy to use:
In [5]: import tabulate
In [6]: unemp = cps.calculate_unemployment_rates([("14", "data/morg_d14.csv"), ("10", "data/morg_d10.csv"), ("07", "data/morg_d07.csv")],
...: (50, 70),
...: cps.GENDER)
...:
In [7]: print(tabulate.tabulate(unemp, unemp.columns.values.tolist(), "fancy_grid", floatfmt=".2f"))
╒════════╤══════╤══════╤══════╕
│ │ 07 │ 10 │ 14 │
╞════════╪══════╪══════╪══════╡
│ Female │ 0.04 │ 0.07 │ 0.05 │
├────────┼──────┼──────┼──────┤
│ Male │ 0.04 │ 0.10 │ 0.06 │
╘════════╧══════╧══════╧══════╛
Take into account that the unemployment rate is computed relative to the number of individuals in each category. So, for example, the above table tells us that, in 2010, 7% of women aged 50-70 and 10% of men aged 50-70 were unemployed. i.e., it does not tell us that 7% of all the individuals aged 50-70 were women and unemployed.
If a MORG dataset does not contain any sample that fits in the age
range for a particular category of var_of_interest, the
unemployment rate should be reported as 0.0 for that category.
For example, in morg_d14_mini.csv, there is no worker in the sample whose race
is W-B-AI, so when we make the following function call:
cps.calculate_unemployment_rates([('14', 'data/morg_d14_mini.csv')], (50, 70), cps.RACE)
the unemployment rate for W-B-AI in the resulting dataframe should
be 0.0. In fact, for this file, the rate should be 0.0 for all
categories except WhiteOnly.
You will need to use the relevant code file to handle this part of
this task. We have defined a dictionary named VAR_TO_FILENAME
that maps a legal var_of_interest value to the corresponding code
filename.
If the list of files is empty or the age range does not make sense
(for example, (70, 50)), your function should return None.
As in previous tasks, we encourage you to first load the datasets,
and see whether you can compute the unemployment rates from IPython.
Once you do so, start implementing the calculate_unemployment_rates
function.
Once you have a calculate_unemployment_rates function, you can
run our basic tests for this function using the Linux command:
py.test -x -k unemployment test_cps.py
Note: Our testing code assumes that the dataframe returned by
calculate_unemployment_rates has a non-categorical index
(i.e., with string values for the index, not categories,
so they can be sorted alphabetically). If you get a
KeyError on the tests, it’s likely you’re returning
a dataframe where the index has categorical values.
This is ok! If you’re code is producing the correct results,
you don’t need to rewrite your code, but you
will have to convert the index to string values before returning
from your function. The way
to do so is non-obvious, so we are providing the exact
code here (assuming the return value of your function
is in a variable called ouput_df):
output_df = output_df.reindex(output_df.index.astype("str")).sort_index()
Once you are sure that the implementation is correct, compare the unemployment rates for both older workers (50 to 70 years old) by gender among 2007, 2010, and 2014 using the full MORG datasets. What does this summary of the data reveal? How about unemployment rates for younger workers between 22 and 29 years old by gender? What if we breakdown the unemployment rates by race or ethnicity?
Submission¶
See these submission instructions if you are working alone.
See these submission instructions if you are working in the same pair as in a previous assignment.
See these submission instructions if you are working in a NEW pair.
Acknowledgments: Yanjing Li wrote the original version of this assignment.