Continuous Integration¶
Any time a software project involves more than one software developer (which is pretty much always), there is the potential for one developer to make changes that could break parts of the code that other developers are working on. Most times, the developer is not aware that they’re doing this; they may be focusing on developing and testing only the specific part of the code they were working on, not realizing that their change broke other features in the code (this is often referred to as a regression).
To address this problem, a common practice is to perform continuous integration (CI): have all developers work on a shared codebase, and have every change to the codebase trigger the running of an extensive set of test cases that cover as much of the code as possible. While you have the ability to run these tests yourself on your machine, having them run automatically every time you push new code can help you catch issues sooner rather than later.
The GitLab server we use in this class has a built-in Continuous Integration server, which means it is possible to automatically check your code for syntax errors and run the tests every time you push your code (and accessing the results through the GitLab web interface). This has many advantages:
- It immediately alerts you to any issues (typically unintended) in your code. Maybe you pushed code that had unresolved Git merge conflicts, or you made a small change that you thought couldn’t possibly break anything (but it did), etc.
- You could have forgotten to add some files to your Git repository. So, it may run correctly on your computer, but not when the code is pulled from scratch from your repository (which is what the graders will do)
- It creates a record of the build/test status of your code. If you need to prove to the instructors that your code was building and/or producing a specific test score, all you need to do is point them to the results of a CI build.
Using GitLab CI¶
Enabling CI for your repository just requires adding a configuration file called .gitlab-ci.yml to the root of your repository. Starting with PA2, we provide a file called ci.yml in the files you pull from upstream. Just take that file, rename it to .gitlab-ci.yml, and add it to the root of your Git repository (not inside your pa2, pa3, etc. directories), and then commit and push it. After that point, every time you push to your master branch, it will trigger a “build” of your code and will run all the tests for that project.
“Building” your code refers to running it through the Python interpreter (without running it) to ensure there are no syntax errors in your code (in compiled languages like C, C++, etc., building typically refers to compiling the code using the compiler). We additionally run your code through a tool called pylint, which can detect certain issues with your code that are not caught by the Python interpreter.
In GitLab CI, the process of building and testing your code after a push is referred to as a pipeline. You can see the pipelines that have been run for your repository by logging into the GitLab server (https://mit.cs.uchicago.edu/), going to your repository, and clicking on the Pipelines link on the left:

The above image shows five pipelines. Each of the pipelines has two stages: a build stage and a test stage. The first (at the bottom) was run just with the distribution files from PA2, so it built correctly (green checkmark), but did not pass the tests (red X). The remaining pipelines fail in various other ways, and the one at the top both builds correctly and passes all the tests. Notice how, if the build stage fails, we skip running the tests (gray “>>) because it makes no sense to run tests on code that has syntax errors, etc.
On the web interface, you can click on individual stages of the pipeline to access the exact output produced by that stage. this can be useful when trying to determine why a build or a test failed:

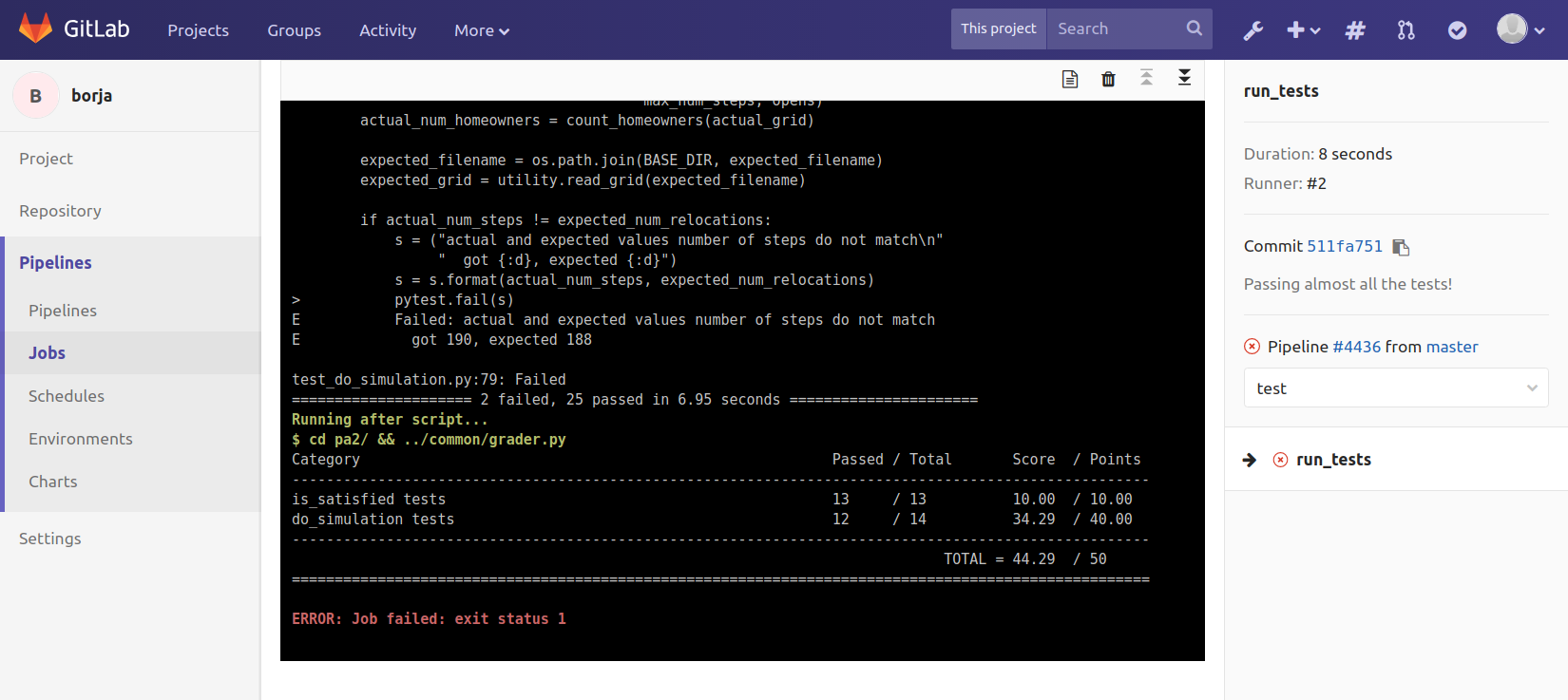
For example, this build failed because of a syntax error in the code:
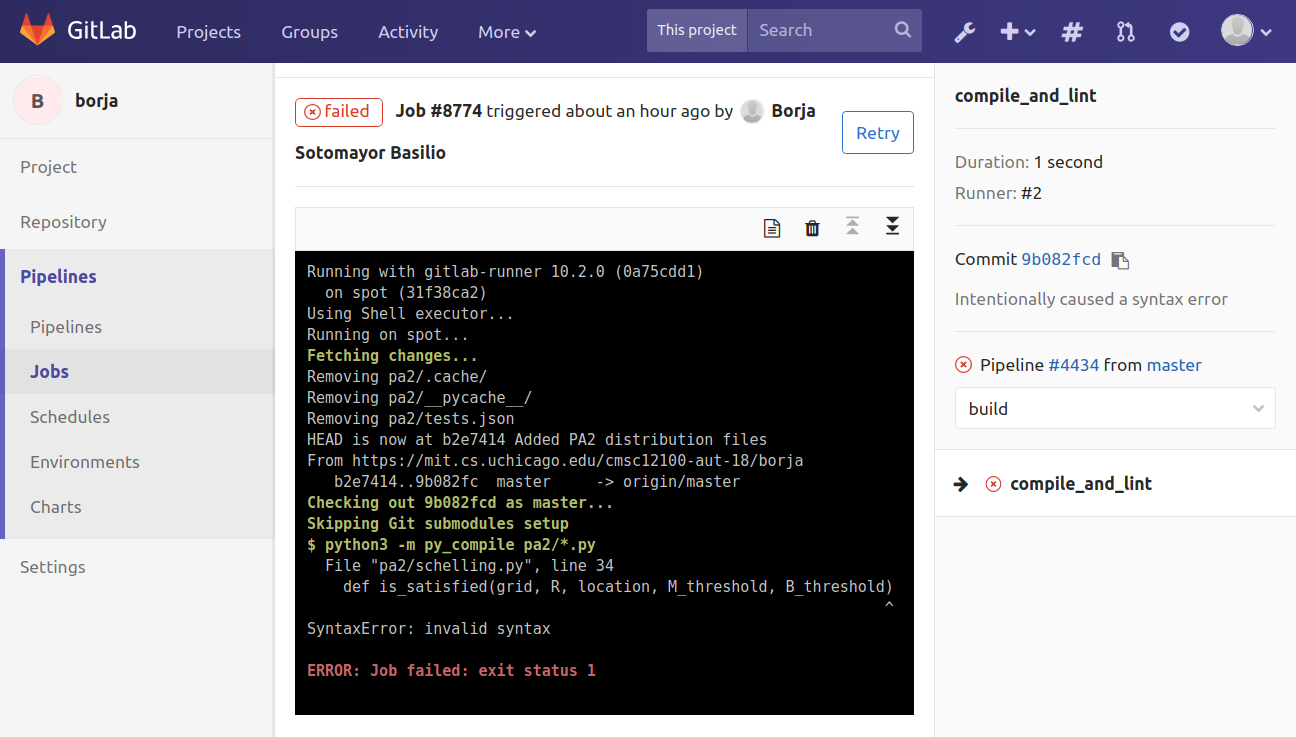
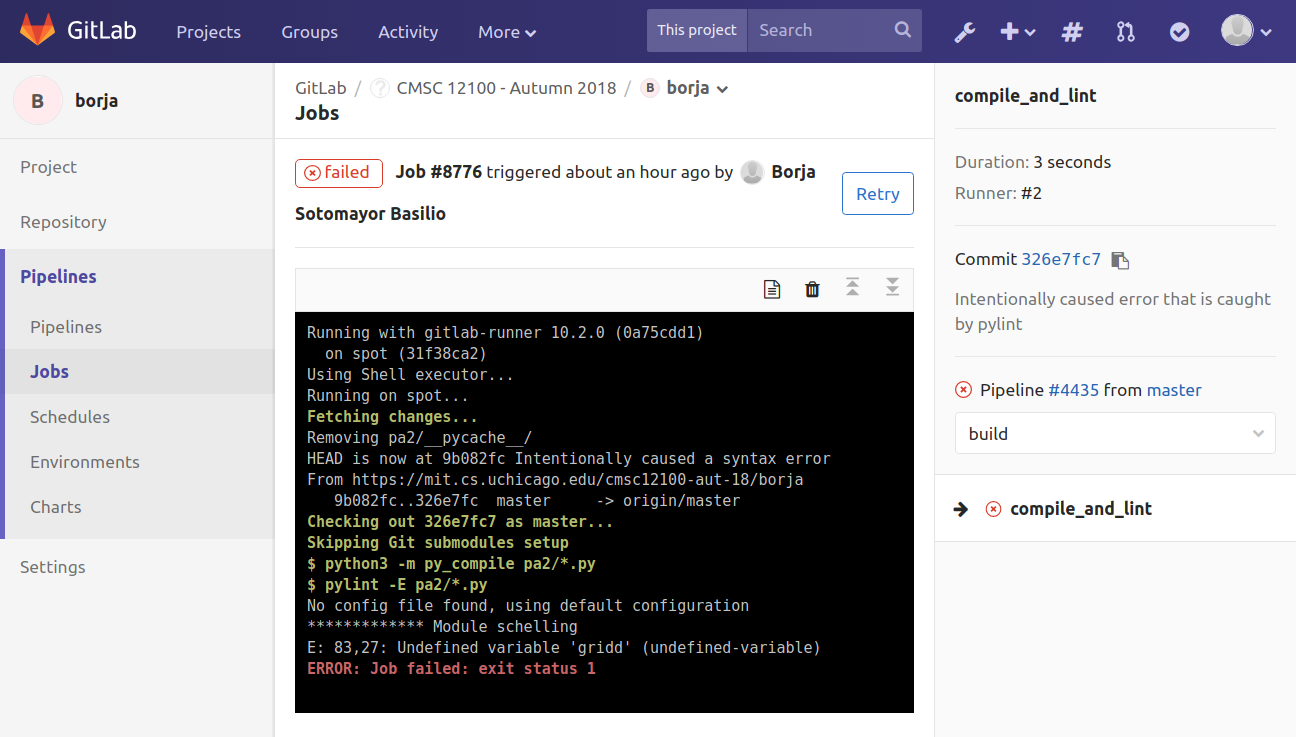
The pylint tool can also catch errors in your code that could cause issues further down the road. For example, here is the output from committing code where we made a typo when referring to a variable (“gridd” instead of “grid”). This issue would likely also make tests fail, but it’s better to catch it sooner rather than later:
If your code builds correctly, then the Continuous Integration will proceed to the test stage. You will only pass this stage if you pass all the tests. If you fail some of the tests, you can click on the test stage to see the output of py.test, which will also include your test score: