Decision Trees¶
Due: Saturday, March 5th at 4:30pm
You may work alone or in a pair for this assignment. If you plan to work in a pair, please read the getting started instructions before you start your work!
The purpose of this assignment is to give you experience with data cleaning and decision trees.
Getting started¶
Using the invitation URL provided on Ed Discussion, create a repository for your PA #5 files.
If you are going to work individually, follow the invitation URL provided on Ed Discussion and, when prompted for a team name, simply enter your CNetID.
If you are going to work in a pair, the process involves a couple of extra steps. The process is described in our Coursework Basics page. Please head over to that page, and return here once you’ve created your team repository.
Next, you will need to initialize your repository. If you are working in a pair only one of you should complete these steps. If you repeat these steps more than once, you may break your repository.
First, create a TEAM variable in the terminal that contains either your CNetID (if you’re working individually) or your team name (if you’re working in a pair):
with your GitHub username):
TEAM=replace_me_with_your_cnetid_or_team_name
(remember you can double-check whether the variable is properly set by running echo $TEAM)
Finally, run these commands (if you don’t recall what some of these commands do, they are explained at the end of the Git Tutorial)::
cd ~/capp30122
git clone git@github.com:uchicago-CAPP30122-win-2022/pa5-$TEAM.git
cd pa5-$TEAM
You will find the files you need for the programming assignment directly in the root of your repository.
Before describing the specifics of your task, we will briefly explain how to work with URLs and grab pages from the web.
Once you have followed these instructions, your repository will
contain a directory named pa5. That directory will include:
decision_tree.py: skeleton code for the tasks.test_decision_tree.py: test code for the tasks.data: a directory with sample data sets.
Pima Indian Data¶
The Pima Indian Data Set, which is from the UC Irvine Machine Learning Repository, contains anonymized information on women from the Pima Indian Tribe. This information was collected by the National Institute of Diabetes and Digestive and Kidney Diseases to study diabetes, which is prevalent among members of this tribe.
The data set has 768 entries, each of which contains the following attributes:
Number of pregnancies
Plasma glucose concentration from a 2 hours in an oral glucose tolerance test
Diastolic blood pressure (mm Hg)
Triceps skin fold thickness (mm)
2-Hour serum insulin (mu U/ml)
Body mass index (weight in kg/(height in m)^2)
Diabetes pedigree function
Age (years)
Has diabetes (1 means yes, 0 means no)
Decision Trees¶
As we discussed in lecture, decision trees are a data structure used to solve classification problems. Here is a sample decision tree that labels tax payers as potential cheaters or non-cheaters.
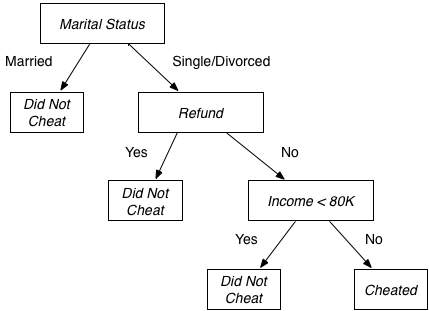
This tree, for example, would classify a single person who did not get a refund and makes $85,000 a year as a possible cheater.
We briefly summarize the algorithm for building decision trees below. See the chapter on Classification and Decision Trees from Introduction to Data Mining by Tan, Steinbach, and Kumar for a more detailed description.
Definitions¶
WARNING: The formulas described in the next two sections are in a slightly different notation then the ones described in lecture; however, they are completely the same. Please refer back to the lecture notes if you are confused.
Before we describe the decision tree algorithm, we need to define a few formulas. Let \(S=A_1 \times A_2 ...\times A_k\) be a multiset of observations, \(r\) a “row” or “observation” in \(S\), \(A \in \{A_1,...,A_k\}\) an attribute set, and \(r[A]\) a row in \(A\). Denote \(|S|\) the number of observed elements in \(S\) (including repetition of the same element.)
We use the following definitions:
to describe the subset of the observations in \(S\) that have value j for attribute \(A\) and the fraction of the observations in \(S\) that have value j for attribute \(A\).
Decision Tree Algorithm¶
Given a multiset of observations \(S\), a target attribute \(T\) (that is, the label we are trying to predict), and a set, \(ATTR\), of possible attributes to split on, the basic algorithm to build a decision tree, based on Hunt’s algorithm, works as follows:
Create a tree node, N, with its class label set to the value from the target attribute \(T\) that occurs most often:
\[ \begin{align}\begin{aligned}\DeclareMathOperator*{\argmax}{argmax}\\\argmax\limits_{v \in values(T)} \, p(S, T, v)\end{aligned}\end{align} \]
where \(values(T)\) is the set of possible values for attribute \(T\) and argmax yields the value \(v\) that maximizes the function. For interior nodes, the class label will be used when a traversal encounters an unexpected value for the split attribute.
If all the observations in \(S\) are from the same target class, \(ATTR\) is the empty set, or the remaining observations share the same values for the attributes in \(ATTR\), return the node N.
Find the attribute \(A\) from \(ATTR\) that yields the largest gain ratio (defined below), set the split attribute for tree node N to be \(A\),and set the children of N to be decision trees computed from the subsets obtained by splitting \(S\) on \(A\) with T as the target class and the remaining attributes (ATTR - {A}) as the set of possible split attributes. The edge from N to the child computed from the subset \(S_{A=j}\) should be labeled \(j\). Stop the recursion if the largest gain ratio is zero.
We use the term gain to describe the increase in purity with respect to attribute \(T\) that can be obtained by splitting the observations in \(S\) according to the value of attribute \(A\). (In less formal terms, we want to identify the attribute that will do the best job of splitting the data into groups such that more of the members share the same value for the target attribute.)
There are multiple ways to define impurity, we’ll use the gini coefficient in this assignment:
Given that definition, we can define gain formally as:
We might see a large gain merely because splitting on an attribute produces many small subsets. To protect against this problem, we will compute a ratio of the gain from splitting on an attribute to the split information for that attribute:
where split information is defined as:
Task: Building and using decision trees¶
We have seeded your pa5 directory with a file named
decision_tree.py. This file includes a main block that processes
the expected command-line arguments–filenames for the training and
testing data–and then calls a function named go. Your task is to
implement go and any necessary auxiliary functions. Your go
function should build a decision tree from the training data and then
return a list (or Pandas series) of the classifications obtained by
using the decision tree to classify each observation in the testing
data.
Your program must be able to handle any data set that:
has a header row,
has categorical attributes, and
in which the (binary) target attribute appears in the last column.
You should use all the columns except the last one as attributes when building the decision tree.
You could break ties in steps 1 and 3 of the algorithm arbitrarily,
but to simplify the process of testing we will dictate a specific
method. In step 1, choose the value that occurs earlier in the
natural ordering for strings, if both classes occur the same number of
times. For example, if "Yes" occurs six times and "No" occurs
six times, choose "No", because "No" < "Yes". In the unlikely
event that the gain ratio for two attributes a1 and a2, where
a1 < a2, is the same, chose a1.
You must define a Python class to represent the nodes of the decision tree. We strongly encourage you to use Pandas for this task as well. It is well suited to the task of computing the different metrics (gini, gain, etc).
Testing We have provided test code for this task in test_decision_tree.py.
Grading¶
Programming assignments will be graded according to a general rubric. Specifically, we will assign points for completeness, correctness, design, and style.
The exact weights for each category will vary from one assignment to another. For this assignment, the weights will be:
Completeness: 60%
Correctness: 15%
Design: 15%
Style: 10%
Obtaining your test score¶
The completeness part of your score will be determined using automated
tests. To get your score for the automated tests, simply run the
following from the Linux command-line. (Remember to leave out the
$ prompt when you type the command.)
$ py.test
$ ./grader.py
Notice that we’re running py.test without the -k or -x
options: we want it to run all the tests. If you’re still failing
some tests, and don’t want to see the output from all the failed
tests, you can add the --tb=no option when running py.test:
$ py.test --tb=no
$ ../grader.py
Take into account that the grader.py program will look at the
results of the last time you ran py.test so, if you make any
changes to your code, you need to make sure to re-run py.test. You
can also just run py.test followed by the grader on one line by
running this:
$ py.test --tb=no; ./grader.py
Cleaning up¶
Before you submit your final solution, you should, remove
any
printstatements that you added for debugging purposes andall in-line comments of the form: “YOUR CODE HERE” and “REPLACE …”
Also, check your code against the style guide. Did you use good variable names? Do you have any lines that are too long, etc.
Do not remove header comments, that is, the triple-quote strings that describe the purpose, inputs, and return values of each function.
As you clean up, you should periodically save your file and run your code through the tests to make sure that you have not broken it in the process.
Submission¶
You must submit your work through Gradescope (linked from our Canvas site). In the “Programming Assignment #5” assignment, simply upload file decision_tree.py (do not upload any other file!). Please note:
You are allowed to make as many submissions as you want before the deadline.
For students working in a pair, one student should upload the pair’s solution and use GradeScope’s mechanism for adding group members to add the second person in the pair.
Please make sure you have read and understood our Late Submission Policy
Your completeness score is determined solely based on the automated tests, but we may adjust your score if you attempt to pass tests by rote (e.g., by writing code that hard-codes the expected output for each possible test input).
Gradescope will report the test score it obtains when running your code. If there is a discrepancy between the score you get when running our grader script, and the score reported by Gradescope, please let us know so we can take a look at it.