Class Meeting 06: Exercise Solutions
On this page you can find solutions to the exercises described in class meeting 06 on Markov decision processes.
Class Exercise #1: Determining MDP Policies with Different Reward Functions
Below you can find the optimal policy for each state given the specified reward function.
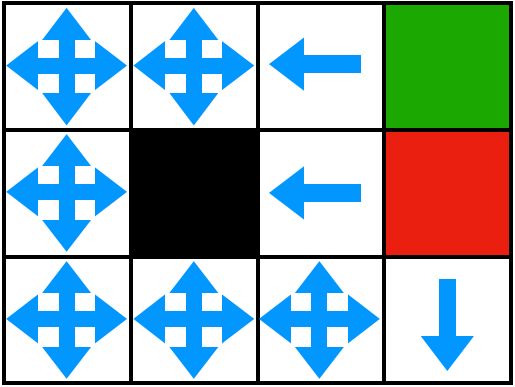
Reward function:
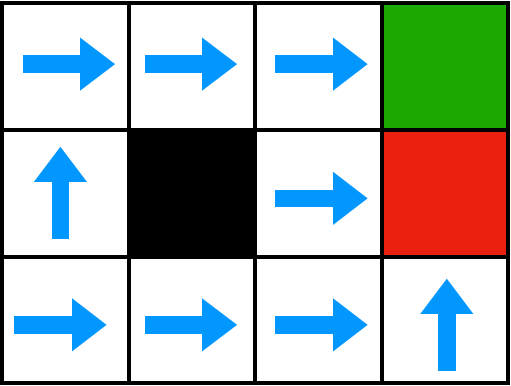
Reward function:
Class Exercise #2: Value Iteration Computation
Below you can find the value computed for each state along each trajectory in the table below according to the Bellman Equation and the specified trajectories.
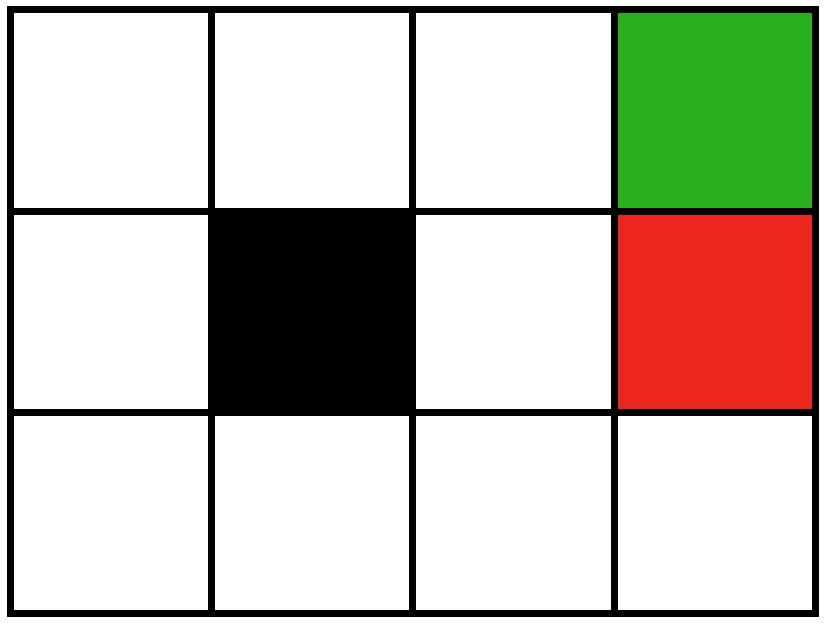
Reward function:
| Trajectory 1 | Trajectory 2 | Trajectory 3 | Trajectory 4 | Trajectory 5 | Trajectory 6 | |
| [0,0] | [0,0] | [0,0] | [0,0] | [0,0] | [0,0] | |
| UP | UP | RIGHT | RIGHT | UP | RIGHT | |
| [1,0] | [1,0] | [0,1] | [0,1] | [1,0] | [0,1] | |
| UP | UP | RIGHT | RIGHT | UP | RIGHT | |
| [2,0] | [2,0] | [0,2] | [0,2] | [2,0] | [0,2] | |
| RIGHT | RIGHT | UP | RIGHT | RIGHT | UP | |
| [2,1] | [2,1] | [1,2] | [0,3] | [2,1] | [1,2] | |
| RIGHT | RIGHT | RIGHT | UP | RIGHT | UP | |
| [2,2] | [2,2] | [1,3] | [1,3] | [2,2] | [2,2] | |
| RIGHT | RIGHT | RIGHT | RIGHT | |||
| [2,3] | [2,3] | [2,3] | [2,3] | |||